Camelot 是 一个python库,它使任何人都可以轻松地从pdf文件中提取表个数据.
Note : 您也可以使用 Excalibur, 它是一个图形化界面的工具,依赖于Camelot !
官方文档地址
官方文档地址: https://camelot-py.readthedocs.io/en/latest/
GitHub地址: https://github.com/socialcopsdev/camelot
用法示例
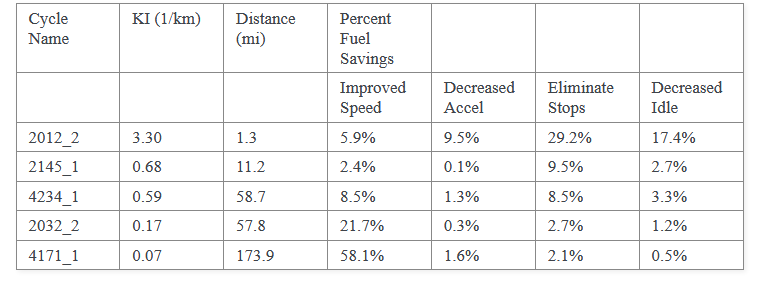
如下是一个示例, 从PDF文件中解析出表格数据, 示例文件.
1 | import camelot |
1 | [ |
安装
以Windows系统为例,其他系统的安装可以参考官方文档地址
1. 安装依赖
根据系统版本的不同以及使用的Python版本,下载相应的依赖包并安装
Tkinter下载地址: https://www.activestate.com/products/activetcl/downloads/
ghostscript下载地址: https://www.ghostscript.com/download.html
2. 校验依赖包
1 | 打开python命令行窗口,输入下方代码,若无报错,则tkinter依赖包安装成功 |
3.安装Camelot
camelot支持以下Python版本: 2.7, 3.5 and 3.6
使用Anaconda进行安装
1
$ conda install -c conda-forge camelot-py
使用pip进行安装
1
$ pip install camelot-py[cv]
源码安装
1
2
3$ git clone https://www.github.com/socialcopsdev/camelot
$ cd camelot
$ pip install ".[cv]"
使用
1. 导入模块
1 | import camelot |
2. 读取PDF文件
1 | tables = camelot.read_pdf('foo.pdf') |
解析表格数据有两种方式,Lattice和stream,默认是Lattice方式,用flavor=’stream’可以修改解析方式.
1 | tables = camelot.read_pdf('foo.pdf',flavor='stream') |
默认读取第一页的表格.若是有表格,会把该页的表格数据存储到TableList对象中,然后可以使用索引的方式逐个获取表格数据.索引从0开始.
3. 查看表格样式
1 | tables[0] |
4. 查看表格信息
1 | print tables[0].parsing_report |
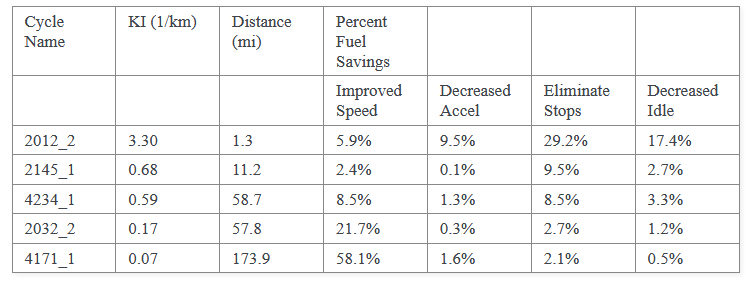
5. 以DataFrame形式获取表格数据
1 | tables[0].df |
6. 导出表格数据
1 | tables[0].to_csv('foo.csv') # to_json(), to_excel() to_html() or to_sqlite() |
7. 分页数据
1 | camelot.read_pdf('your.pdf', pages='1,2,3') # pages=1,4-10,20-30 or pages=1,4-10,20-end |
8. 读取有密码的文件
1 | tables = camelot.read_pdf('foo.pdf', password='userpass') |
9. 读取有背景颜色的文件
1 | tables = camelot.read_pdf('background_lines.pdf', process_background=True) |
10. 获取表格样式
先安装依赖: $ pip install camelot-py[plot]
样式总共有以下几种:
‘text’
‘grid’
‘contour’
‘line’
‘joint’
‘textedge’
其中: ‘line’和 ‘joint’ 仅适用于Lattice, ‘textedge’仅适用于Stream.
1 | camelot.plot(tables[0], kind='text') |
11. Specify table areas
1 | tables = camelot.read_pdf('table_areas.pdf', flavor='stream', table_areas=['316,499,566,337']) |
12. Specify table regions
1 | tables = camelot.read_pdf('table_regions.pdf', table_regions=['170,370,560,270']) |
13. Split text along separators
1 | tables = camelot.read_pdf('column_separators.pdf', flavor='stream', columns=['72,95,209,327,442,529,566,606,683'], split_text=True) |
14. Strip characters from text
1 | tables = camelot.read_pdf('12s0324.pdf', flavor='stream', strip_text=' .\n') |
15. 其他功能
详细请参考官方文档
API Reference
1. Main Interface
1 | camelot.read_pdf(filepath, pages='1', password=None, flavor='lattice', suppress_stdout=False, layout_kwargs={}, **kwargs) |
2. Lower-Level Classes
1 | class camelot.handlers.PDFHandler(filepath, pages='1', password=None) |
1 | class camelot.parsers.Stream(table_regions=None, table_areas=None, columns=None, split_text=False, flag_size=False, strip_text='', edge_tol=50, row_tol=2, column_tol=0, **kwargs) |
1 | class camelot.parsers.Lattice(table_regions=None, table_areas=None, process_background=False, line_scale=15, copy_text=None, shift_text=['l', 't'], split_text=False, flag_size=False, strip_text='', line_tol=2, joint_tol=2, threshold_blocksize=15, threshold_constant=-2, iterations=0, resolution=300, **kwargs) |
3. Lower-Lower-Level Classes
1 | class camelot.core.TableList(tables)[source] |

