- SQLite的数据库URI在Linux或macOS系统下的斜线数量是4个;在Windows系统下的URI中的斜线数量为3个。
内存型数据库的斜线固定为3个。 - 常用的SQLAlchemy字段参数中,index如果设置为True,则表示为该字段创建索引
- 通过ORM模型查看对应的SQL建表语句
1 | #!/usr/bin/env python |
1 | >>> from app import db,Note |
- filter与filter_by查询方法的区别
1 | # filter |
- 编辑操作
当我们渲染表单字段时,如果表单字段的data属性不为空,WTForms会自动把data属性的值添加到表单字段的value属性中,作为表单的值填充进去,我们不用手动为value属性赋值。因此,将存储笔记原有内容的note.body属性赋值给表单body字段的data属性即可在页面上的表单中填入原有的内容。
1 | # index.html |
1 | class EditNoteForm(FlaskForm): |
- 正常且安全的删除操作:
大多数人通常会考虑在笔记内容下添加一个删除链接:
1 | id) }}">Delete</a>```,这个链接指向用来删除笔记的delete_note视图: |
但这种处理方式实际上会使程序处于CSRF攻击的风险之中。
防范CSRF攻击的基本原则就是正确使用GET和POST方法。像删除这类修改数据的操作绝对不能通过GET请求实现,正确的做法是为删除操作创建一个表单:
1 | class DeleteNoteForm(FlaskForm): |
这个表单类只有一个提交字段,只需要在页面上显示一个删除按钮来提交表单。删除表单的提交请求由delete_note视图处理:
1 |
|
html页面如下:
1 | <form method="post" action="{{ url_for('delete_note', note_id=note.id) }}"> |
表单的action属性设置为删除当前笔记的URL。构建URL时,URL变量note_id的值通过note.id属性获取,当单击提交按钮时,会将请求发送到action属性中的URL。
添加删除表单的主要目的就是防止CSRF攻击,所以不要忘记渲染CSRF令牌字段form.csrf_token。
- 一对多关系
Author类用来表示作者,Article类用来表示文章,一个作者可以有多篇文章
1 | class Author(db.Model): |
(1) 定义外键
外键只能存储单一数据(标量),所以外键总是在“多”这一侧定义。
定义一个author_id字段作为外键,使用db.ForeignKey类定义为外键,传入关系另一侧的表名和主键字段名,即author.id。
实际的效果是将article表的author_id的值限制为author表的id列的值。
外键字段的命名没有限制。
(2) 定义关系属性
关系属性在关系的出发侧定义,即一对多关系的“一”这一侧。
定义了一个articles属性来表示对应的多篇文章。关系属性的名称没有限制,可以自由修改。它相当于一个快捷查询,不会作为字段写入数据库中。
这个属性并没有使用Column类声明为列,而是使用了db.relationship()关系函数定义为关系属性,因为这个关系属性返回多个记录,我们称之为集合关系属性。
relationship()函数的第一个参数为关系另一侧的模型名称,它会告诉SQLAlchemy将Author类与Article类建立关系。
当这个关系属性被调用时,SQLAlchemy会找到关系另一侧(即article表)的外键字段(即author_id),然后反向查询article表中所有author_id值为当前表主键值(即author.id)的记录,返回包含这些记录的列表,也就是返回某个作者对应的多篇文章记录。
( 3 ) 示例
1 | # 添加数据 |
对关系属性调用remove()方法可以与对应的Aritcle对象解除关系:
1 | >>> foo.articles.remove(ham) |
(4)建立双向关系
在某些情况下,也许希望能在Article类中定义一个类似的author关系属性,当被调用时返回对应的作者记录,这类返回单个值的关系属性被称为标量关系属性。
而这种两侧都添加关系属性获取对方记录的关系我们称之为双向关系。
通过在关系的另一侧也创建一个relationship()函数,就可以在两个表之间建立双向关系。
1 | class Writer(db.Model): |
- 多对一关系
Ctizen类表示居民,City类表示城市。
在多对一关系中外键和关系属性都定义在“多”这一侧,即City类中。
1 | class Citizen(db.Model): |
- 一对一关系
Cuntry类表示国家,Capital类表示首都。
一对一关系实际上是通过建立双向关系的一对多关系的基础上转化而来。在定义集合属性的关系函数中将uselist参数设为False,这时一对多关系将被转换为一对一关系。
“多”这一侧本身就是标量关系属性,不用做任何改动。而“一”这一侧的集合关系属性,通过将uselist设为False后,将仅返回对应的单个记录,而且无法再使用列表语义操作.
1 | class Country(db.Model): |
- 多对多关系
Sudent类表示学生,Teacher类表示老师。
在多对多关系中,每一个记录都可以与关系另一侧的多个记录建立关系,关系两侧的模型都需要存储一组外键。
除了关系两侧的模型外,还需要创建一个关联表。关联表不存储数据,只用来存储关系两侧模型的外键对应关系。
关联表使用db.Table类定义,传入的第一个参数是关联表的名称。
关联表中定义了两个外键字段:teacher_id字段存储Teacher类的主键,student_id存储Student类的主键。
借助关联表这个中间人存储的外键对,可以把多对多关系分化成两个一对多关系.
对关系属性使用append()方法即可。如果你想要解除关系,那么可以使用remove()方法。
关联表由SQLAlchemy接管,它会帮我们管理这个表:我们只需要像往常一样通过操作关系属性来建立或解除关系,SQLAlchemy会自动在关联表中创建或删除对应的关联表记录,而不用手动操作关联表。
1 | association_table = db.Table('association', |
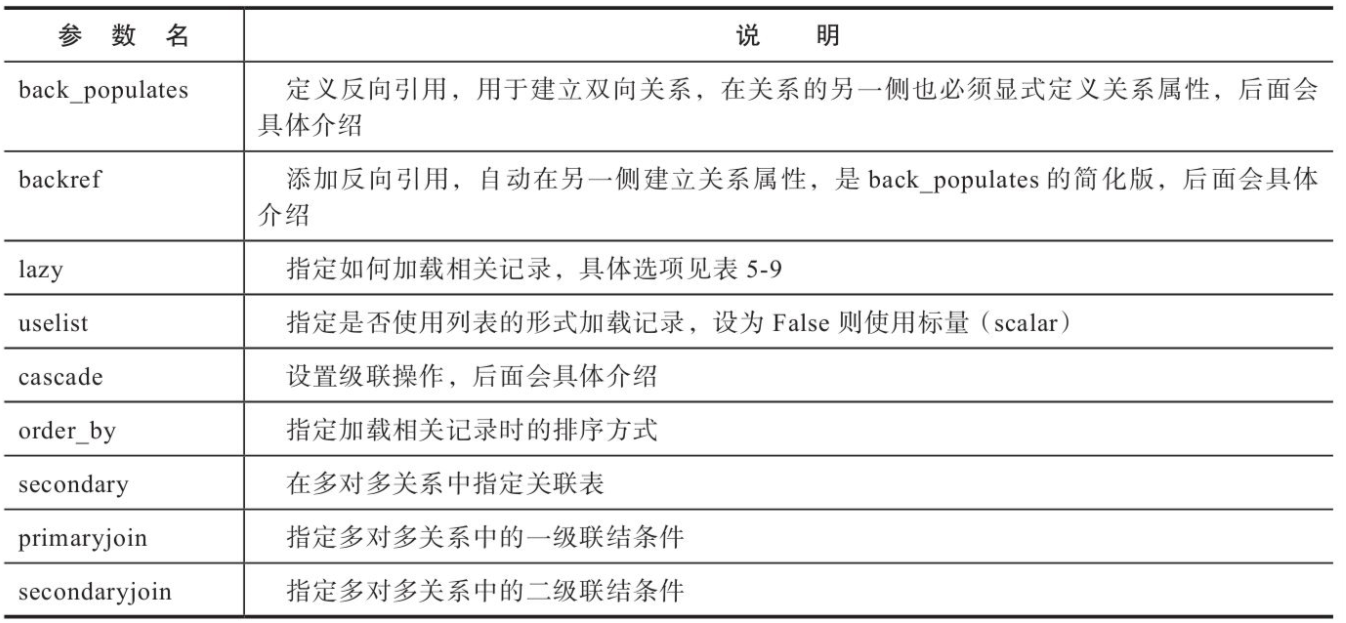
常用的SQLAlchemy关系函数参数
常用的SQLAlchemy关系记录加载方式(lazy参数可选值)
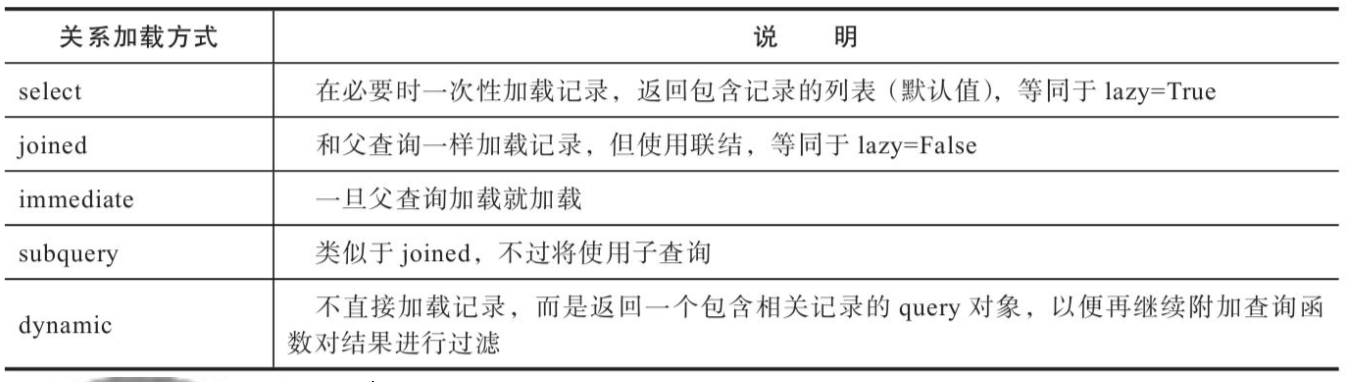
dynamic选项仅用于集合关系属性,不可用于多对一、一对一或是在关系函数中将uselist参数设为False的情况。
- 级联操作
Cascade意为“级联操作”,就是在操作一个对象的同时,对相关的对象也执行某些操作。
通过一个Post模型和Comment模型来演示级联操作,分别表示文章(帖子)和评论,两者为一对多关系:
1 | class Post(db.Model): |
级联行为通过关系函数relationship()的cascade参数设置。
设置了cascade参数的一侧将被视为父对象,相关的对象则被视为子对象。cascade通常使用多个组合值,级联值之间使用逗号分隔,
1 | class Post(db.Model): |
常用的配置组合如下所示:
- save-update、merge(默认值)
- save-update、merge、delete
- all
- all、delete-orphan
当没有设置cascade参数时,会使用默认值save-update、merge。
all等同于除了delete-orphan以外所有可用值的组合,即save-update、merge、refresh-expire、expunge、delete。
(1) save-update
save-update是默认的级联行为,当cascade参数设为save-update时,如果使用db.session.add()方法将Post对象添加到数据库会话时,
那么与Post相关联的Comment对象也将被添加到数据库会话。
(2) delete
如果某个Post对象被删除,那么按照默认的行为,该Post对象相关联的所有Comment对象都将与这个Post对象取消关联,外键字段的值会被清空。
如果Post类的关系函数中cascade参数设为delete时,这些相关的Comment会在关联的Post对象删除时被一并删除。
当需要设置delete级联时,我们会将级联值设为all或save-update、merge、delete。
1 | class Post(db.Model): |
(3) delete-orphan
delete-orphan基于delete级联的,必须和delete级联一起使用,通常会设为all、delete-orphan,因为all包含delete。
因此当cascade参数设为delete-orphan时,它首先包含delete级联的行为:当某个Post对象被删除时,所有相关的Comment对象都将被删除(delete级联)。除此之外,当某个Post对象(父对象)与某个Comment对象(子对象)解除关系时,也会删除该Comment对象,这个解除关系的对象被称为孤立对象(orphan object).
1 | class Post(db.Model): |
delete和delete-orphan通常会在一对多关系模式中,而且“多”这一侧的对象附属于“一”这一侧的对象时使用。尤其是如果“一”这一侧的“父”对象不存在了,那么“多”这一侧的“子”对象不再有意义的情况。
- 事件监听
SQLAlchemy也提供了一个listen_for()装饰器,它可以用来注册事件回调函数。
listen_for()装饰器主要接收两个参数,target表示监听的对象,这个对象可以是模型类、类实例或类属性等。identifier参数表示被监听事件的标识符,比如,用于监听属性的事件标识符有set、append、remove、init_scalar、init_collection等。
1 | class Draft(db.Model): |
listen_for()装饰器中分别传入Draft.body和set作为targe和identifier参数的值。
监听函数接收所有set()事件方法接收的参数,其中的target参数表示触发事件的模型类实例,使用target.edit_time即可获取我们需要叠加的字段。
其他的参数也需要照常写出,虽然这里没有用到。
value表示被设置的值,oldvalue表示被取代的旧值。
当set事件发生在目标对象Draft.body上时,这个监听函数就会被执行,从而自动叠加Draft.edit_time列的值
1 | >>> draft = Draft(body='init') |
还有一种更简单的方法。
通过在listen_for()装饰器中将关键字参数name设为True,可以在监听函数中接收**kwargs作为参数(可变长关键字参数),即“named argument”。然后在函数中可以使用参数名作为键来从**kwargs字典获取对应的参数值:
1 |
|

