GIL(全局解释器锁)
GIL面试题如下
描述Python GIL的概念, 以及它对python多线程的影响?编写一个多线程抓取网页的程序,并阐明多线程抓取程序是否可比单线程性能有提升,并解释原因。
Guido的声明:http://www.artima.com/forums/flat.jsp?forum=106&thread=214235
he language doesn’t require the GIL – it’s only the CPython virtual machine that has historically been unable to shed it.
单线程死循环
单独执行该文件会占满一个CPU核心数(相当于单进程单线程),两个窗口执行该文件会占满两个CPU核心数(相当于两进程两线程)
1 | #!/usr/bin/env python |
两个线程死循环
单独执行该文件每个CPU核心会占一半(单进程两线程)
1 | #!/usr/bin/env python |
两个进程死循环
单独执行该文件会占满二个CPU核心数
1 | #!/usr/bin/env python |
总结:多线程并不是真正的并行,而是伪并行,也就是并发。原因就是因为线程有GIL全局解释器锁。只有进程才是真正的并行
参考答案
- Python语言和GIL没有半毛钱关系。仅仅是由于历史原因在Cpython虚拟机(C语言解释器)中难以移除GIL。(其他python解释器没有GIL,比如java语言写的jpython解释器)
- GIL:全局解释器锁。每个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程可以执行代码。
- 线程释放GIL锁的情况: 在IO操作等可能会引起阻塞的system call之前,可以暂时释放GIL,但在执行完毕后,必须重新获取GIL Python 3.x使用计时器(执行时间达到阈值后,当前线程释放GIL)或Python 2.x,tickets计数达到100
计算密集型:程序没有延时,一直在计算数据;IO密集型:输入输出,读写操作
线程和协程适用于IO密集型,计算密集型考虑使用进程。- Python使用多进程是可以利用多核的CPU资源的。
- 多线程爬取比单线程性能有提升,因为遇到IO阻塞会自动释放GIL锁
使用c语言来解决GIL问题
子线程使用的是c语言的函数,此时单独执行该文件,会占满两个CPU核心
1 | from ctypes import * |
如何解决GIL
- 换python解释器,不使用Cpython解释器,使用jpython解释器等
- 用其他语言来替代线程中的代码,不如上例中的c语言,(胶水语言)
深拷贝、浅拷贝
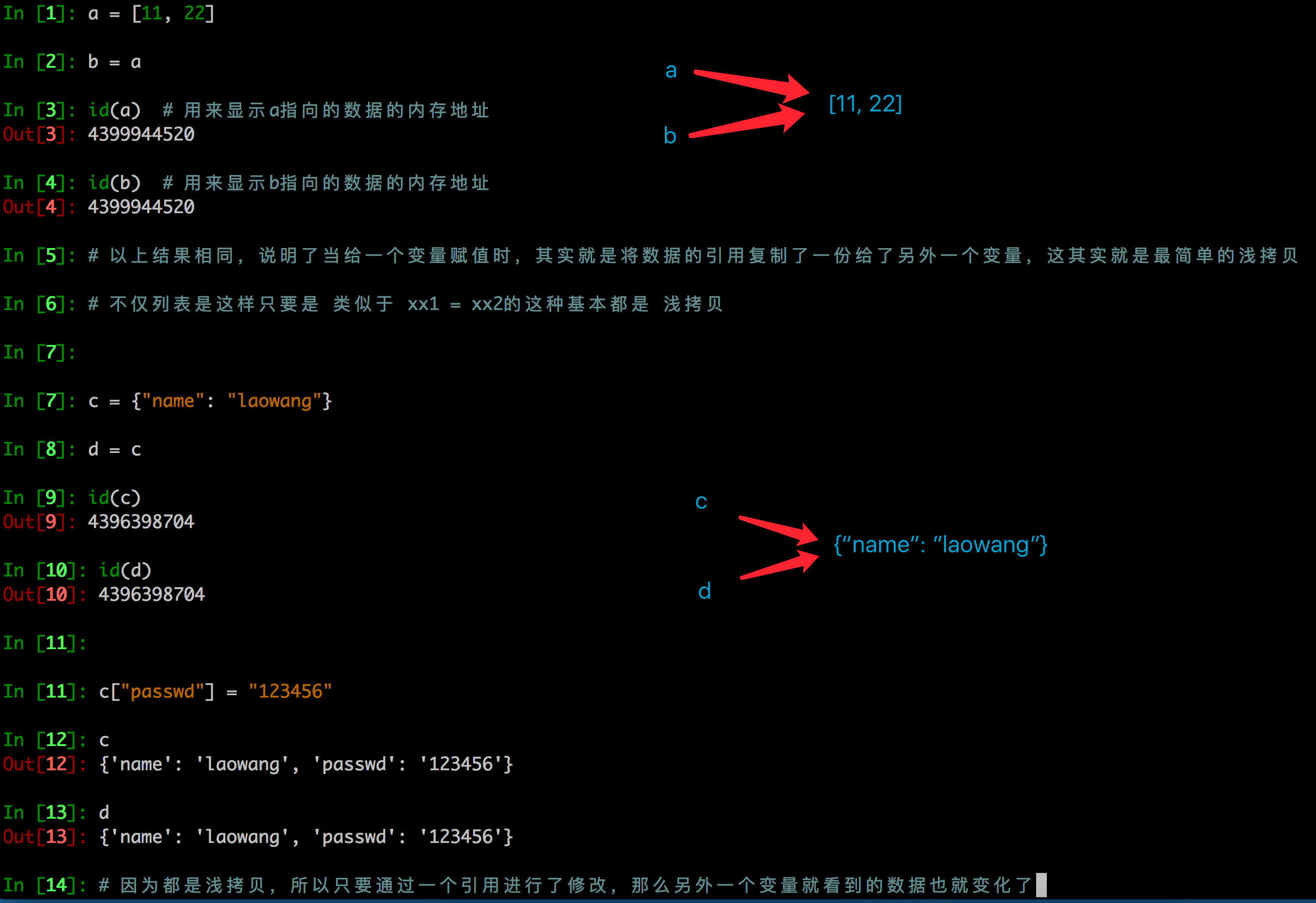
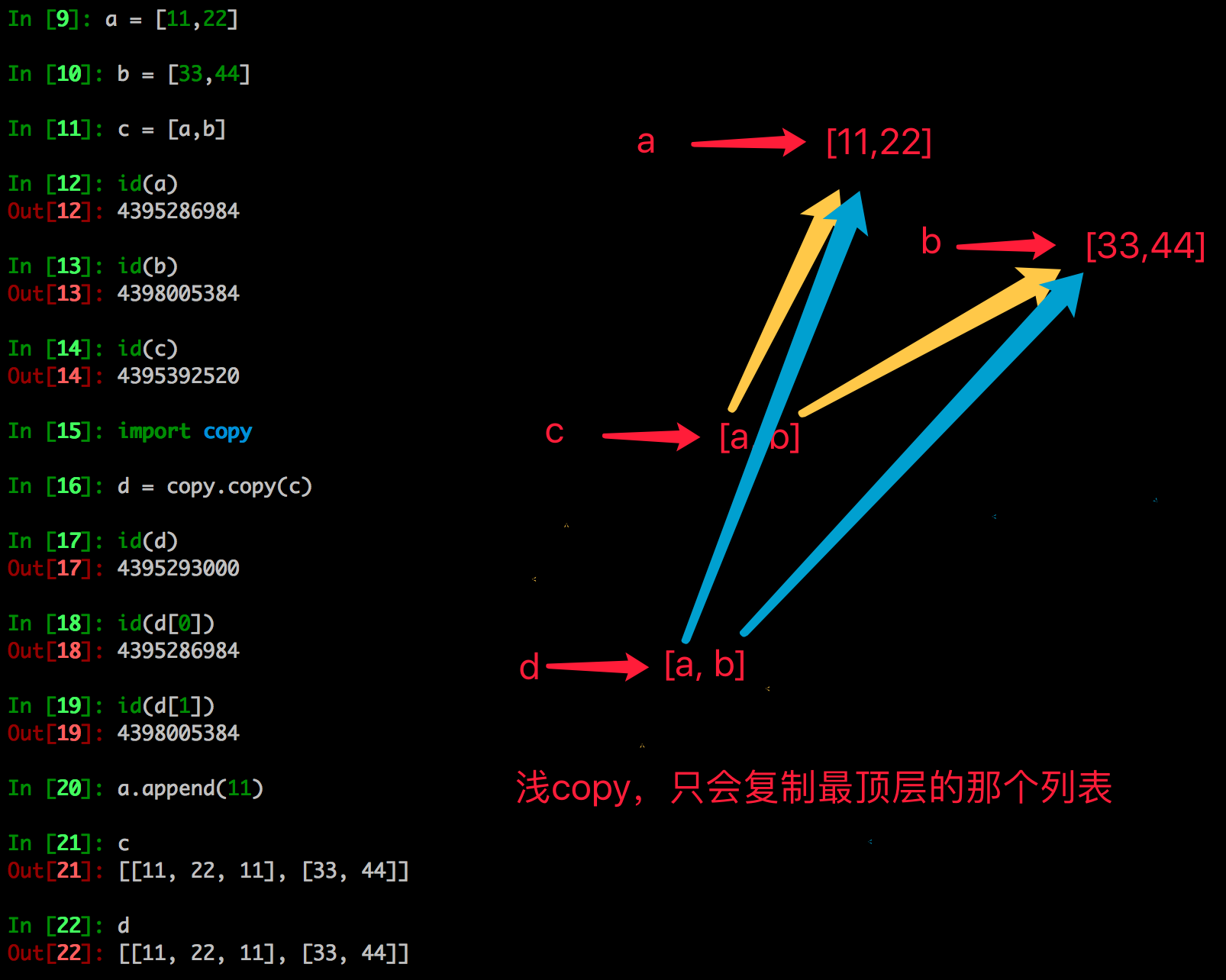
1. 浅拷贝
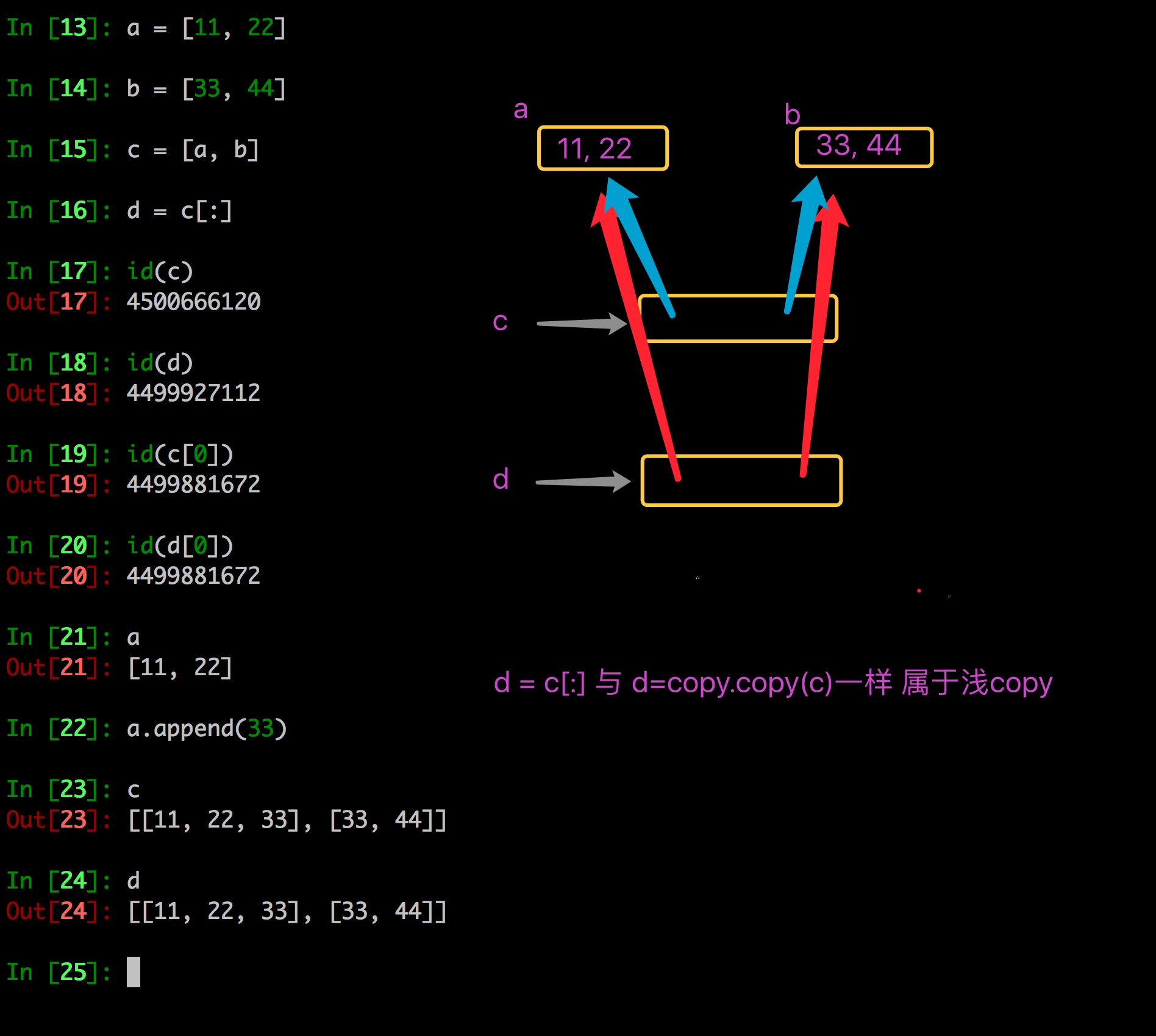
- 浅拷贝是对于一个对象的顶层拷贝
通俗的理解是:拷贝了引用,并没有拷贝内容
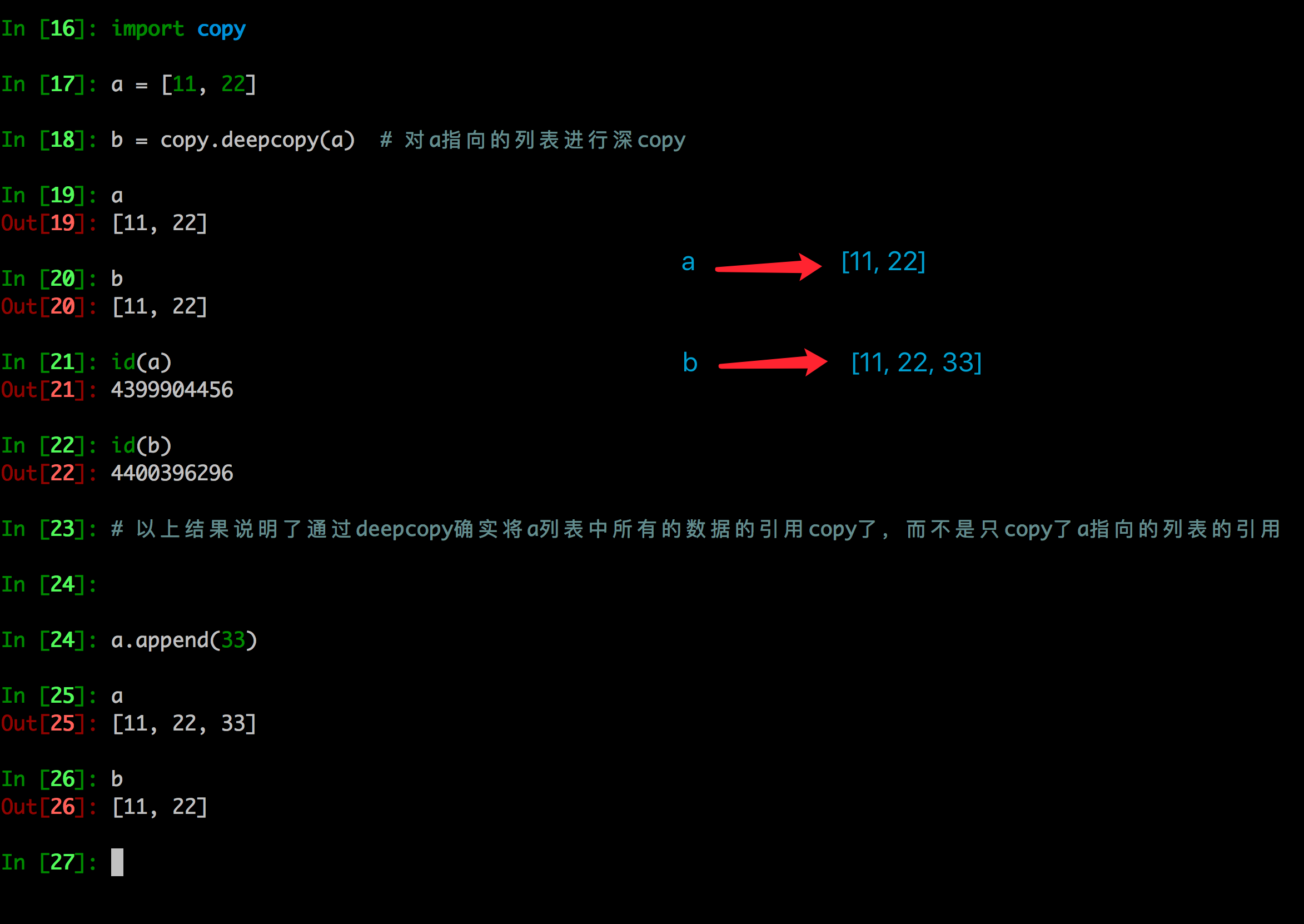
2. 深拷贝
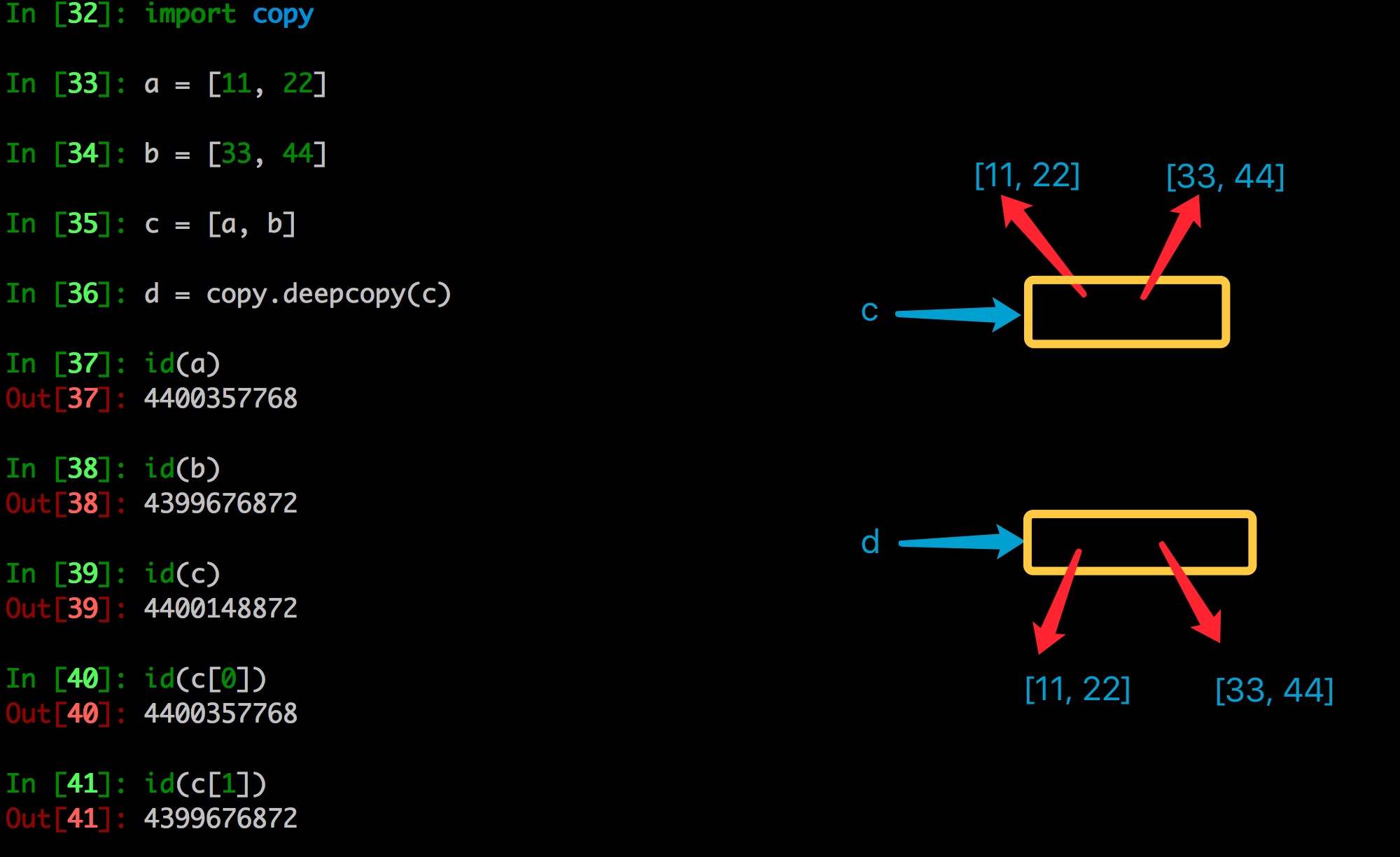
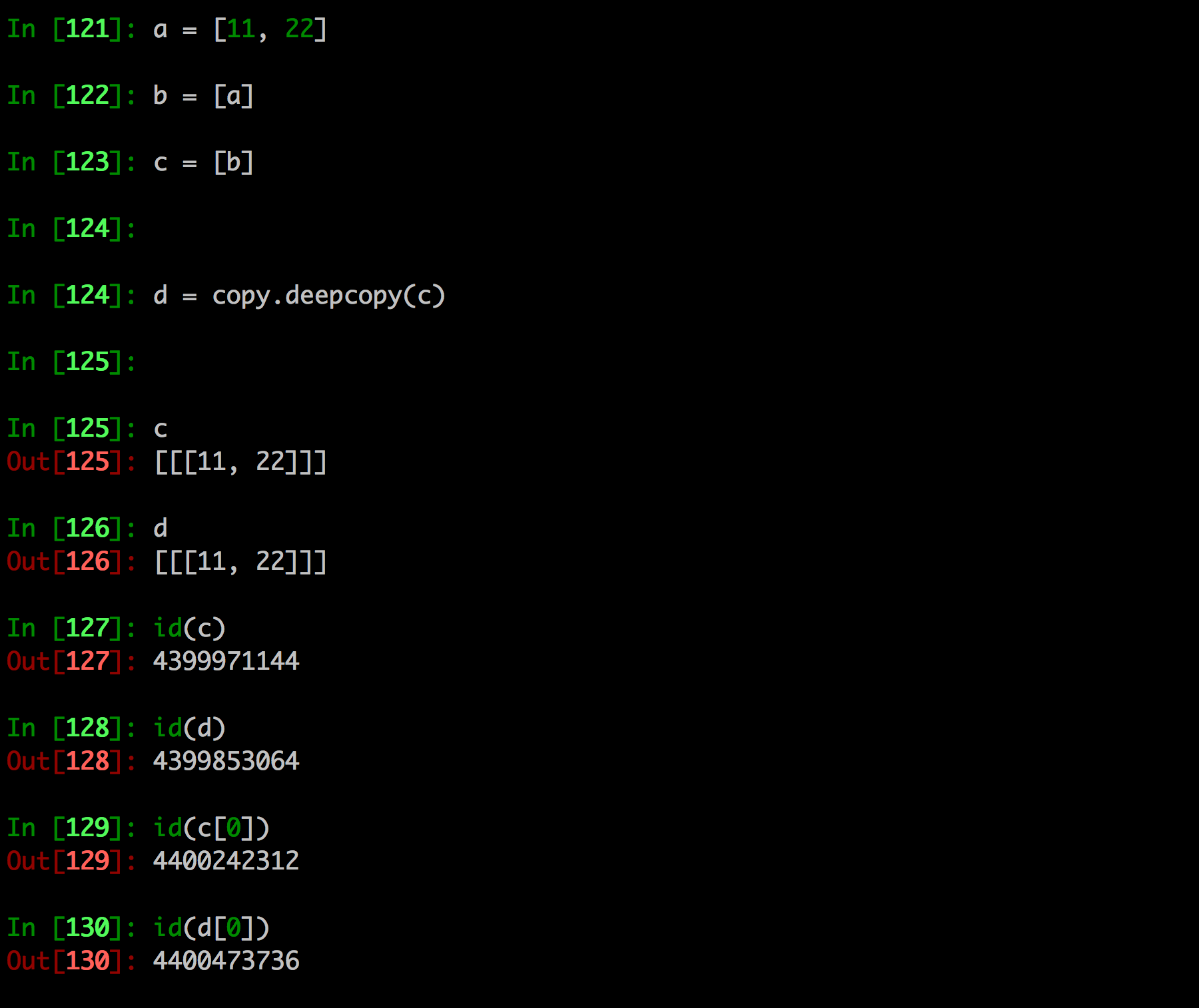
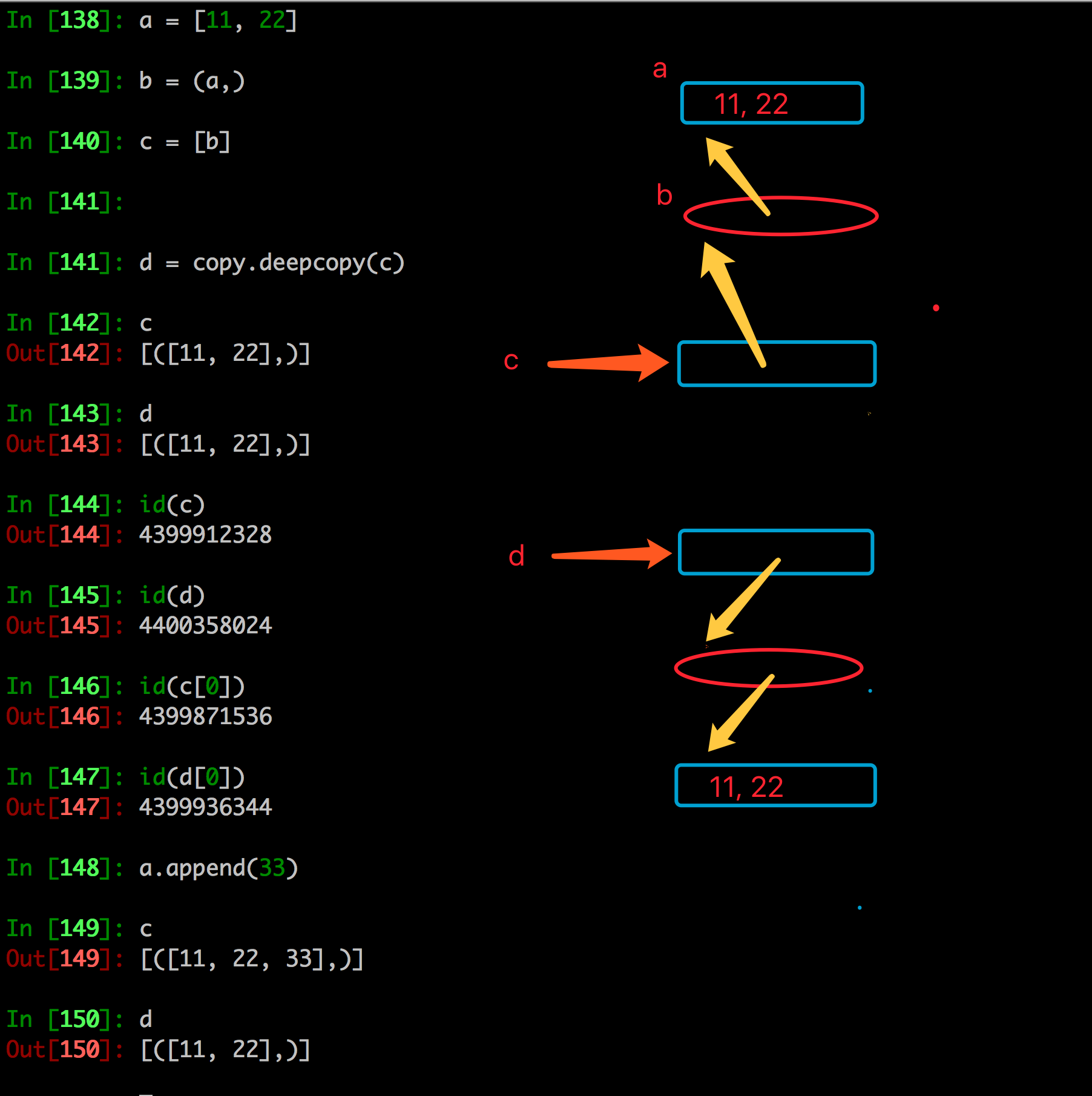
- 深拷贝是对于一个对象所有层次的拷贝(递归)
进一步理解深拷贝
3. 拷贝的其他方式
- 分片表达式可以赋值一个序列
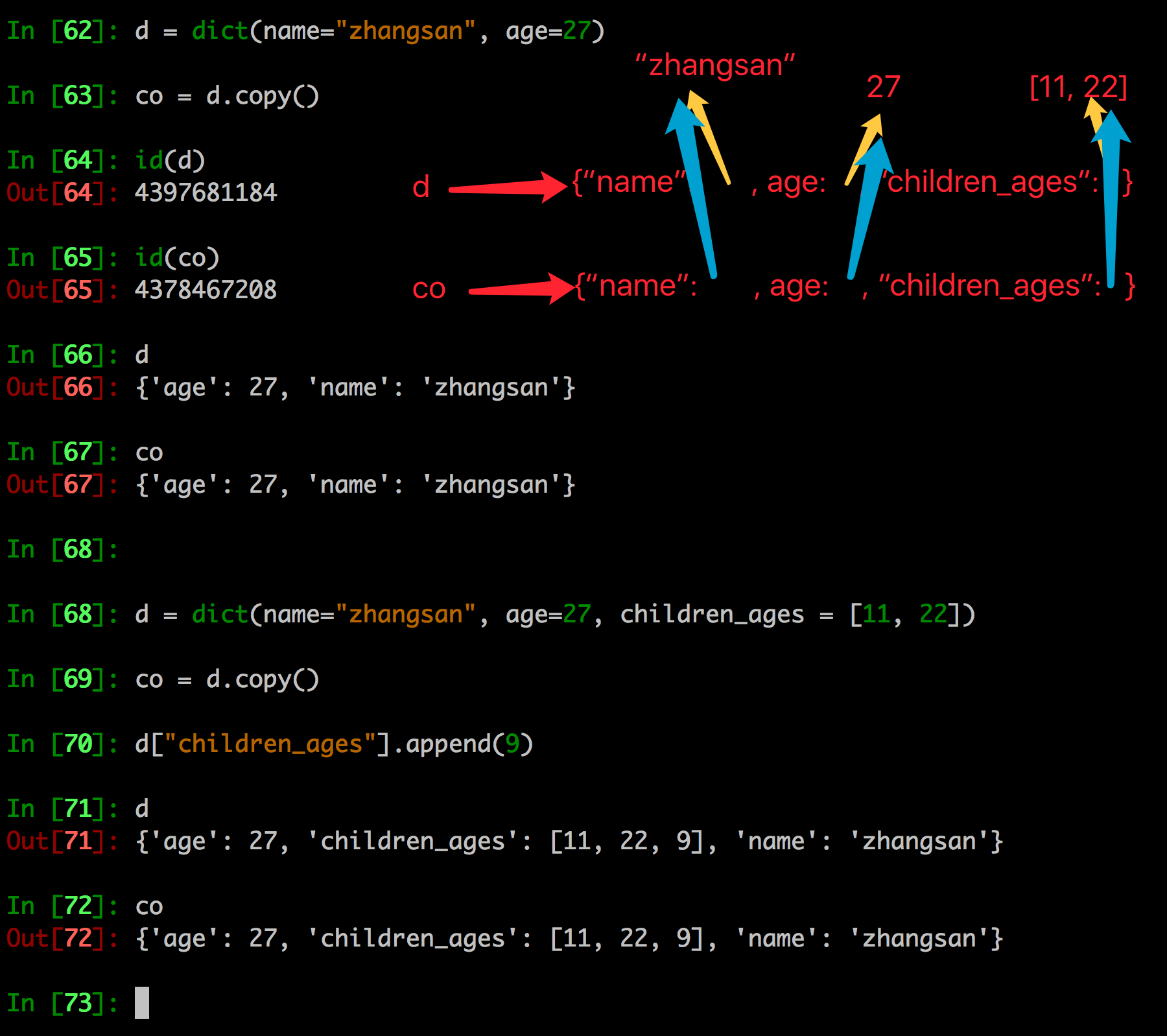
- 字典的copy方法可以拷贝一个字典
4. 注意点
浅拷贝对不可变类型和可变类型的copy不同
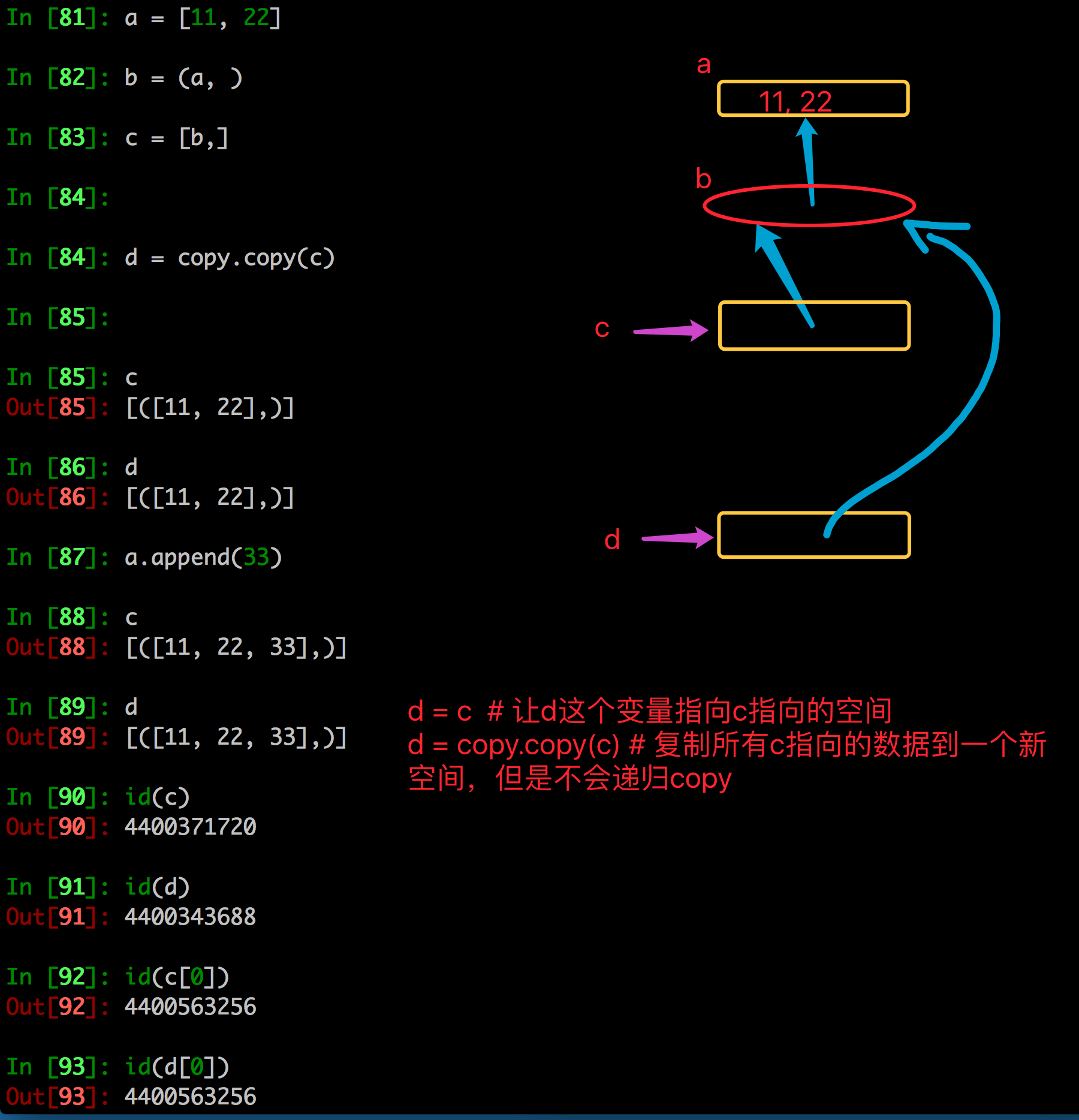
- copy.copy对于可变类型,会进行浅拷贝
- copy.copy对于不可变类型,不会拷贝,仅仅是指向
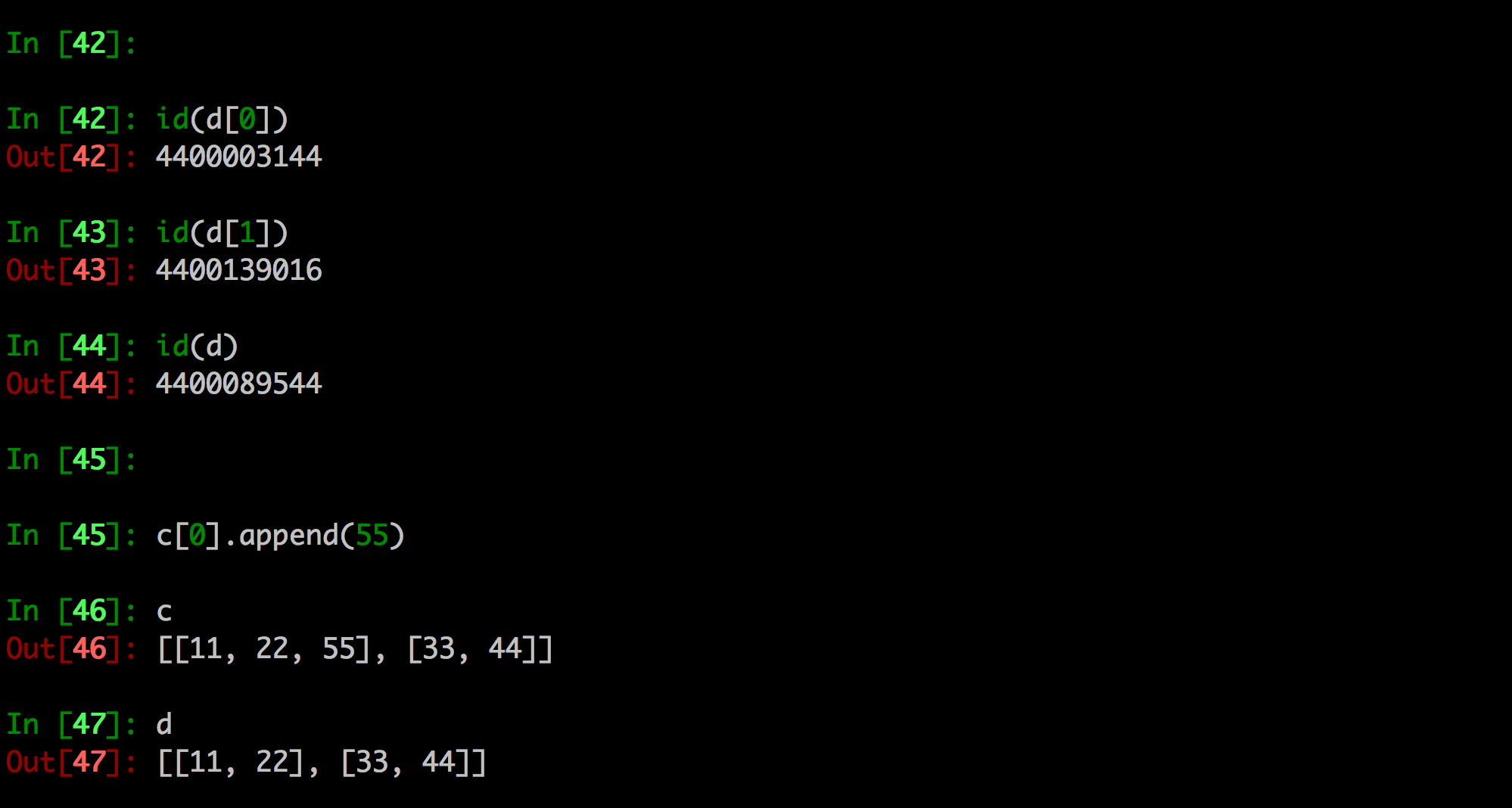
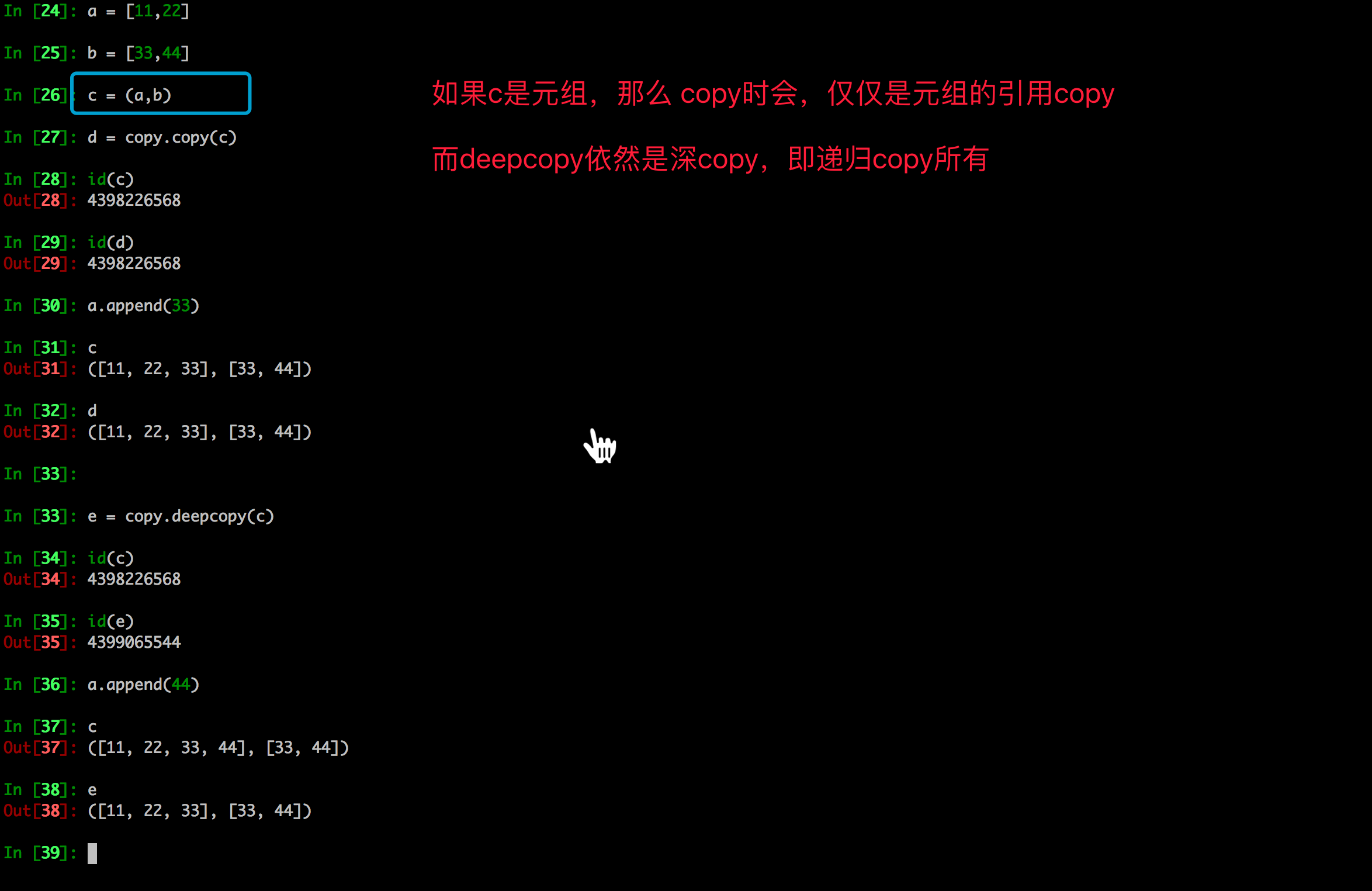
比如:如果copy.copy拷贝的是元组,那么它不会进行浅拷贝,仅仅是指向
原因:因为元组是不可变类型,那么意味着数据一定不能修改,因此用copy.copy的时候它会自动判断,如果是元组它就指向了它
1 | In [88]: a = [11,22,33] |
如果用copy.copy或者copy.deepcopy对一个全部都是不可变类型的数据进行拷贝,那么他们结果相同的,都是引用指向
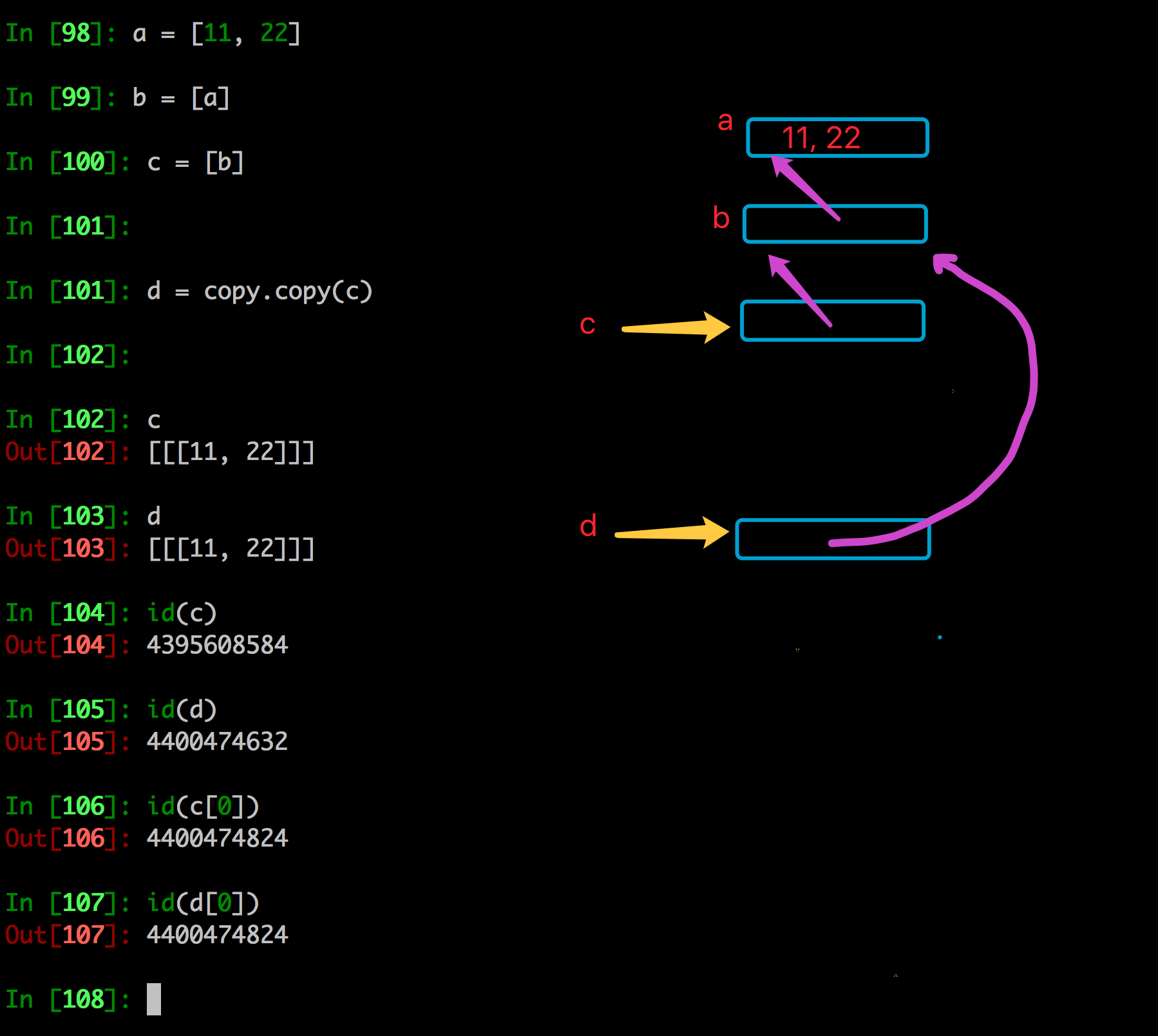
如果拷贝的是一个拥有可变类型的数据,即使元组是最顶层,copy.deepcopy依然是深拷贝,而copy.copy还是指向。
1 | In[37]: a = [11,22] |
copy.copy和copy.deepcopy的区别
copy.copy
copy.deepcopy

私有化
- xx: 公有变量
_x: 单前置下划线,私有化属性或方法,from module import * 禁止导入,类对象和子类可以访问__xx:双前置下划线,避免与子类中的属性命名冲突,无法在外部直接访问(名字重整所以访问不到)__xx__:双前后下划线,用户名字空间的魔法对象或属性。例如:__init__, __ 不要自己发明这样的名字xx_:单后置下划线,用于避免与Python关键词的冲突
通过name mangling(名字重整(目的就是以防子类意外重写基类的方法或者属性)如:_Classobject)机制就可以访问private了。(在 名称 前面加上 _类名 => _类名名称)
1 | #coding=utf-8 |
_名的变量、函数、类在使用from xxx import *时都不会被导入,类对象和子类可以访问- 父类中属性名为
__名字的,子类不继承,子类不能访问,子类可以通过父类中的其他方法间接访问 - 如果在子类中向
__名字赋值,那么会在子类中定义一个与父类相同名字的属性
import导入模块
1. import 搜索路径

路径搜索
- 从上面列出的目录里依次查找要导入的模块文件
- 开头的第一个‘’ 表示当前路径
- 列表中的路径的先后顺序代表了python解释器在搜索模块时的先后顺序
程序执行时添加新的模块路径
1 | sys.path.append('/home/itcast/xxx') |
2. 重新导入模块
模块被导入后,import module不能重新导入模块,重新导入需用reload




3. 多模块开发时的注意点
1 | recv_msg.py模块 |


再议 封装、继承、多态
封装、继承、多态 是面向对象的3大特性
为啥要封装
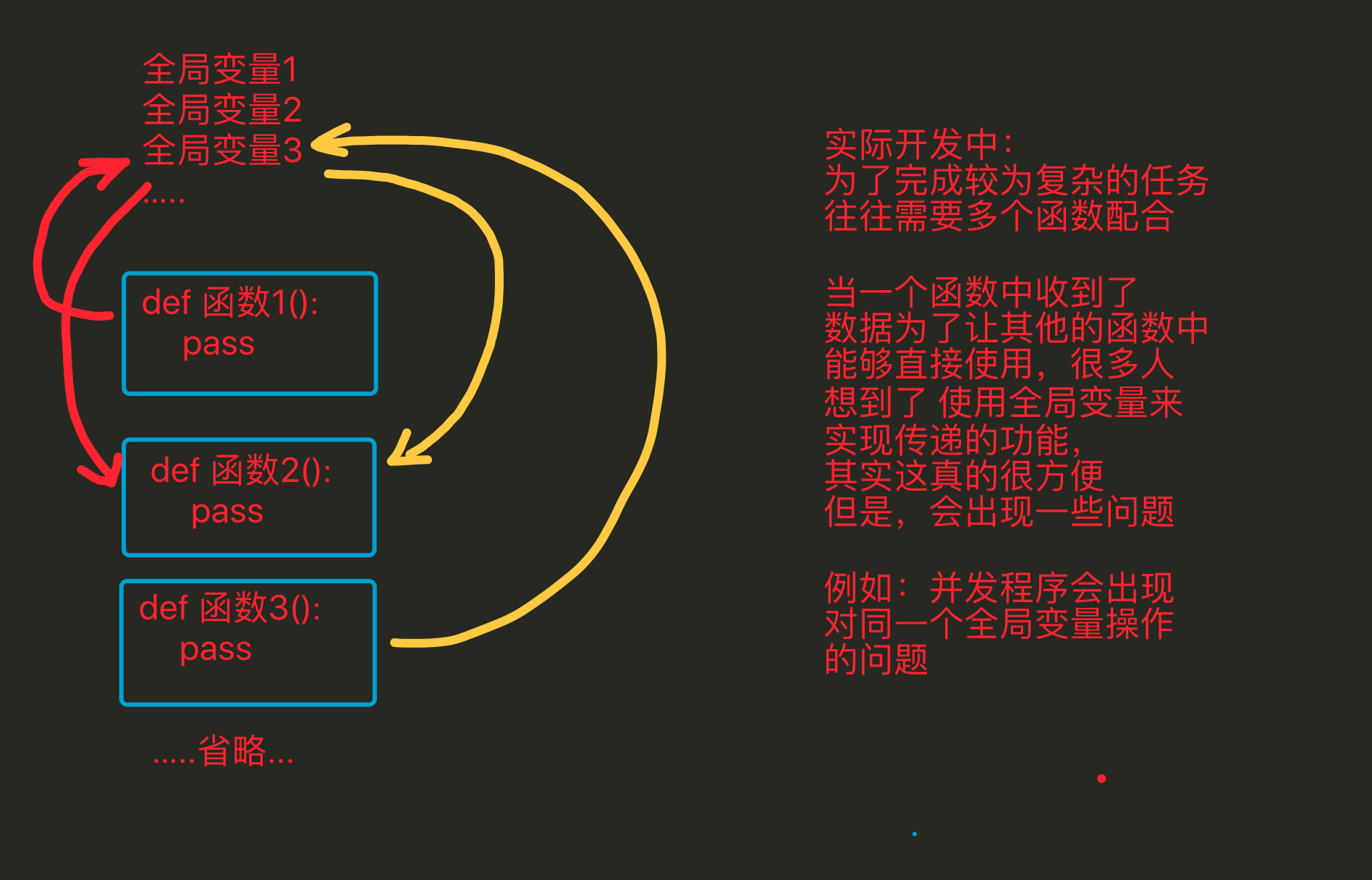

好处
- 在使用面向过程编程时,当需要对数据处理时,需要考虑用哪个模板中哪个函数来进行操作,但是当用面向对象编程时,因为已经将数据存储到了这个独立的空间中,这个独立的空间(即对象)中通过一个特殊的变量(class)能够获取到类(模板),而且这个类中的方法是有一定数量的,与此类无关的将不会出现在本类中,因此需要对数据处理时,可以很快速的定位到需要的方法是谁 这样更方便
- 全局变量是只能有1份的,多很多个函数需要多个备份时,往往需要利用其它的变量来进行储存;而通过封装 会将用来存储数据的这个变量 变为了对象中的一个“全局”变量,只要对象不一样那么这个变量就可以再有1份,所以这样更方便
- 代码划分更清晰
面向过程
1 | 全局变量1 |
面向对象
1 | class 类(object): |
为啥要继承

说明
- 能够提升代码的重用率,即开发一个类,可以在多个子功能中直接使用
- 继承能够有效的进行代码的管理,当某个类有问题只要修改这个类就行,而其继承这个类的子类往往不需要就修改
怎样理解多态
1 | class MiniOS(object): |
运行结果
1 | Linux 安装的软件列表为 [] |
多继承以及MRO顺序
1. 单独调用父类的方法
父类被调用多次
1 | # coding=utf-8 |
运行结果:
1 | ******多继承使用类名.__init__ 发生的状态****** |
2. 多继承中super调用有所父类的被重写的方法
使用super方法父类被调用一次
1 | print("******多继承使用super().__init__ 发生的状态******") |
运行结果:
1 | ******多继承使用super().__init__ 发生的状态****** |
注意:
- 以上2个代码执行的结果不同
- 如果2个子类中都继承了父类,当在子类中通过父类名调用时,parent被执行了2次
- 如果2个子类中都继承了父类,当在子类中通过super调用时,parent被执行了1次
3. 单继承中super
1 | print("******单继承使用super().__init__ 发生的状态******") |
运行结果:
1 | ******单继承使用super().__init__ 发生的状态****** |
总结
- super().init相对于类名.init,在单继承上用法基本无差
- 但在多继承上有区别,super方法能保证每个父类的方法只会执行一次,而使用类名的方法会导致方法被执行多次,具体看前面的输出结果
- 多继承时,使用super方法,对父类的传参数,应该是由于python中super的算法导致的原因,必须把参数全部传递,否则会报错
- 单继承时,使用super方法,则不能全部传递,只能传父类方法所需的参数,否则会报错
- 多继承时,相对于使用类名.init方法,要把每个父类全部写一遍, 而使用super方法,只需写一句话便执行了全部父类的方法,这也是为何多继承需要全部传参的一个原因
小试牛刀(以下为面试题)
以下的代码的输出将是什么? 说出你的答案并解释。
2
3
4
5
6
7
8
9
10
11
12
13
14
x = 1
class Child1(Parent):
pass
class Child2(Parent):
pass
print(Parent.x, Child1.x, Child2.x)
Child1.x = 2
print(Parent.x, Child1.x, Child2.x)
Parent.x = 3
print(Parent.x, Child1.x, Child2.x)
答案, 以上代码的输出是:
1 | 1 1 1 |
使你困惑或是惊奇的是关于最后一行的输出是 3 2 3 而不是 3 2 1。为什么改变了 Parent.x 的值还会改变 Child2.x 的值,但是同时 Child1.x 值却没有改变?
这个答案的关键是,在 Python 中,类变量在内部是作为字典处理的。如果一个变量的名字没有在当前类的字典中发现,将搜索祖先类(比如父类)直到被引用的变量名被找到(如果这个被引用的变量名既没有在自己所在的类又没有在祖先类中找到,会引发一个 AttributeError 异常 )。
因此,在父类中设置 x = 1 会使得类变量 x 在引用该类和其任何子类中的值为 1。这就是因为第一个 print 语句的输出是 1 1 1。
随后,如果任何它的子类重写了该值(例如,我们执行语句 Child1.x = 2),然后,该值仅仅在子类中被改变。这就是为什么第二个 print 语句的输出是 1 2 1。
最后,如果该值在父类中被改变(例如,我们执行语句 Parent.x = 3),这个改变会影响到任何未重写该值的子类当中的值(在这个示例中被影响的子类是 Child2)。这就是为什么第三个 print 输出是 3 2 3。
自己的想法,按顺序解析
print(Parent.x, Child1.x, Child2.x),其中Parent.x是调用Parent类中的x属性,输出结果是1;Child1.x是输出Child1类中的x属性,本类没有的话则到父类中查找,父类Parent中有,则输出结果是1;Child2.x同理。
Child1.x = 2相当于给Child1类添加一个类属性。
print(Parent.x, Child1.x, Child2.x),其中Parent.x是调用Parent类中的x属性,输出结果是1;Child1.x是输出Child1类中的x属性,本类中有这个属性则直接输出,不用到父类中查找,输出的结果是2;Child2.x还是从父类中查找,输出结果是1。
Parent.x = 3相当于修改父类Parent中x类属性的值。
print(Parent.x, Child1.x, Child2.x),其中Parent.x是调用Parent类中的x属性,输出结果是3;Child1.x是输出Child1类中的x属性,本类中有这个属性则直接输出,不用到父类中查找,输出的结果是2;Child2.x还是从父类中查找,输出结果是3。
再论静态方法和类方法
1. 类属性、实例属性
它们在定义和使用中有所区别,而最本质的区别是内存中保存的位置不同,
- 实例属性属于对象
- 类属性属于类
1 | class Province(object): |
由上述代码可以看出【实例属性需要通过对象来访问】【类属性通过类访问】,在使用上可以看出实例属性和类属性的归属是不同的。
其在内容的存储方式类似如下图: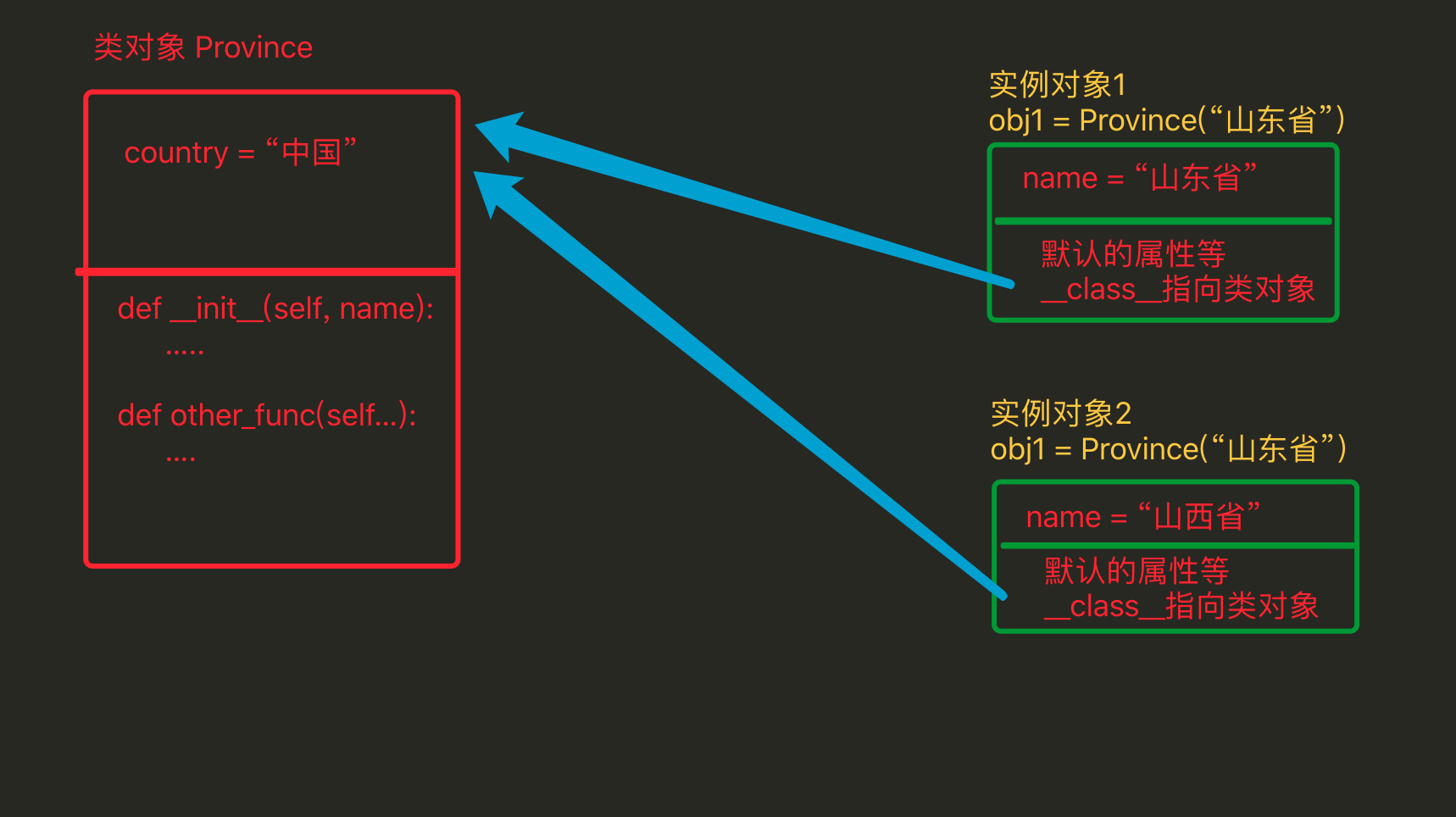
由上图看出:
- 类属性在内存中只保存一份
- 实例属性在每个对象中都要保存一份
应用场景:
- 通过类创建实例对象时,如果每个对象需要具有相同名字的属性,那么就使用类属性,用一份即可
2. 实例方法、静态方法和类方法
方法包括:实例方法、静态方法和类方法,三种方法在内存中都归属于类,区别在于调用方式不同。
- 实例方法:由对象调用;至少一个self参数;执行实例方法时,自动将调用该方法的对象赋值给self;
- 类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类赋值给cls;
- 静态方法:由类调用;无默认参数;
1 | class Foo(object): |
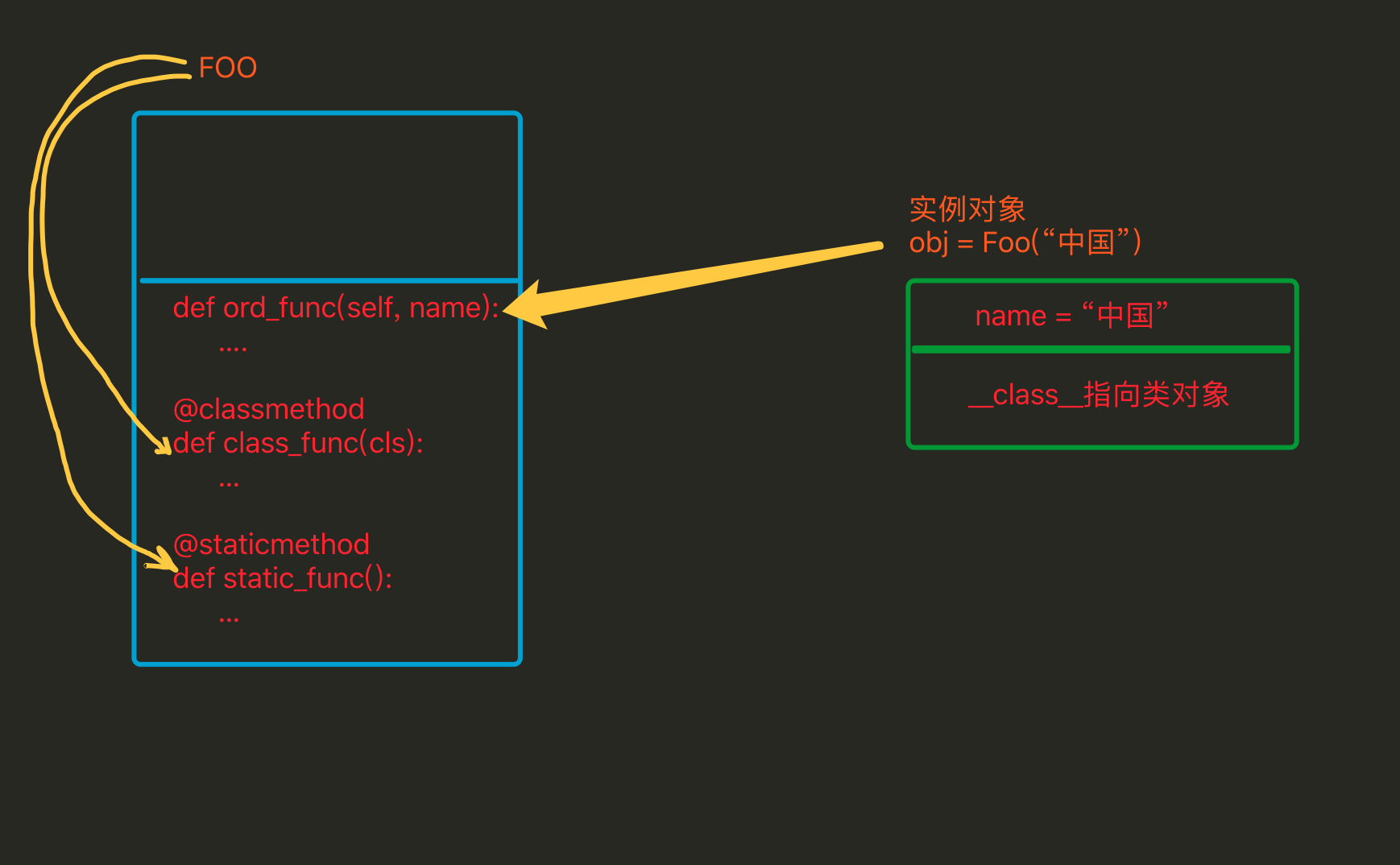
对比
- 相同点:对于所有的方法而言,均属于类,所以在内存中也只保存一份
- 不同点:方法调用者不同、调用方法时自动传入的参数不同
property属性
1. 什么是property属性
一种用起来像是使用的实例属性一样的特殊属性,可以对应于某个方法
1 | # ######## 定义 ######## |
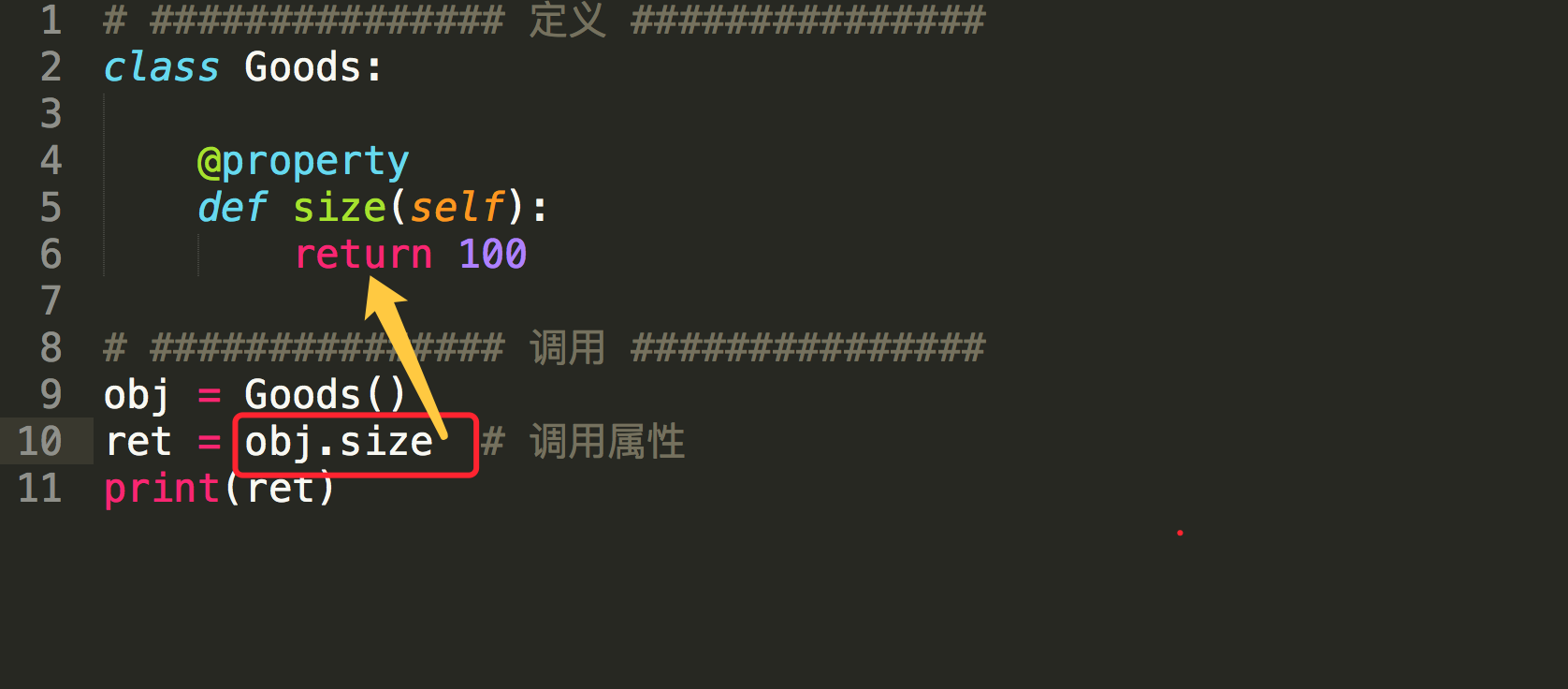
property属性的定义和调用要注意一下几点:
- 定义时,在实例方法的基础上添加 @property 装饰器;并且仅有一个self参数
- 调用时,无需括号
1 | 方法:foo_obj.func() |
2. 简单的实例
对于京东商城中显示电脑主机的列表页面,每次请求不可能把数据库中的所有内容都显示到页面上,而是通过分页的功能局部显示,所以在向数据库中请求数据时就要显示的指定获取从第m条到第n条的所有数据 这个分页的功能包括:
- 根据用户请求的当前页和总数据条数计算出 m 和 n
- 根据m 和 n 去数据库中请求数据
1 | # ######## 定义 ######## |
从上述可见
- Python的property属性的功能是:property属性内部进行一系列的逻辑计算,最终将计算结果返回。
3. property属性的有两种方式
- 装饰器 即:在方法上应用装饰器
- 类属性 即:在类中定义值为property对象的类属性
3.1 装饰器方式
在类的实例方法上应用@property装饰器
Python中的类有经典类和新式类,新式类的属性比经典类的属性丰富。( 如果类继object,那么该类是新式类 )
3.1.1经典类,具有一种@property装饰器
1 | ########## 定义 ######## |
3.1.2 新式类,具有三种@property装饰器
1 | #coding=utf-8 |
注意
- 经典类中的属性只有一种访问方式,其对应被 @property 修饰的方法
- 新式类中的属性有三种访问方式,并分别对应了三个被@property、@方法名.setter、@方法名.deleter修饰的方法
由于新式类中具有三种访问方式,我们可以根据它们几个属性的访问特点,分别将三个方法定义为对同一个属性:获取、修改、删除
1 | class Goods(object): |
3.2 类属性方式
- 当使用类属性的方式创建property属性时,
经典类和新式类无区别1
2
3
4
5
6
7
8
9class Foo:
def get_bar(self):
return 'laowang'
BAR = property(get_bar)
obj = Foo()
reuslt = obj.BAR # 自动调用get_bar方法,并获取方法的返回值
print(reuslt)
property方法中有个四个参数
- 第一个参数是方法名,调用 对象.属性 时自动触发执行方法
- 第二个参数是方法名,调用 对象.属性 = XXX 时自动触发执行方法
- 第三个参数是方法名,调用 del 对象.属性 时自动触发执行方法
- 第四个参数是字符串,调用 对象.属性.doc ,此参数是该属性的描述信息
1 | #coding=utf-8 |
由于类属性方式创建property属性具有3种访问方式,我们可以根据它们几个属性的访问特点,分别将三个方法定义为对同一个属性:获取、修改、删除
1 | class Goods(object): |
4. Django框架中应用了property属性(了解)
WEB框架 Django 的视图中 request.POST 就是使用的类属性的方式创建的属性
1 | class WSGIRequest(http.HttpRequest): |
5. 总结
- 定义property属性共有两种方式,分别是【装饰器】和【类属性】,而【装饰器】方式针对经典类和新式类又有所不同。
- 通过使用property属性,能够简化调用者在获取数据的流程
property属性-应用
1. 私有属性添加getter和setter方法
1 | class Money(object): |
2. 使用property升级getter和setter方法
1 | class Money(object): |
3. 使用property取代getter和setter方法
- 重新实现一个属性的设置和读取方法,可做边界判定
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Money(object):
def __init__(self):
self.__money = 0
# 使用装饰器对money进行装饰,那么会自动添加一个叫money的属性,当调用获取money的值时,调用装饰的方法
def money(self):
return self.__money
# 使用装饰器对money进行装饰,当对money设置值时,调用装饰的方法
def money(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
a = Money()
a.money = 100
print(a.money)
魔法属性
无论人或事物往往都有不按套路出牌的情况,Python的类属性也是如此,存在着一些具有特殊含义的属性,详情如下:
1. __doc__
- 表示类的描述信息
1
2
3
4
5
6
7class Foo:
""" 描述类信息,这是用于看片的神奇 """
def func(self):
pass
print(Foo.__doc__)
#输出:类的描述信息
2. __module__ 和 __class__
__module__表示当前操作的对象在那个模块__class__表示当前操作的对象的类是什么1
2
3
4
5
6
7
8
9
10
11
12test.py
# -*- coding:utf-8 -*-
class Person(object):
def __init__(self):
self.name = 'laowang'
main.py
from test import Person
obj = Person()
print(obj.__module__) # 输出 test 即:输出模块
print(obj.__class__) # 输出 test.Person 即:输出类
3. __init__
- 初始化方法,通过类创建对象时,自动触发执行
1
2
3
4
5
6
7class Person:
def __init__(self, name):
self.name = name
self.age = 18
obj = Person('laowang') # 自动执行类中的 __init__ 方法
4. __del__
- 当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以,del的调用是由解释器在进行垃圾回收时自动触发执行的。1
2
3class Foo:
def __del__(self):
pass
5. __call__
- 对象后面加括号,触发执行。
注:__init__方法的执行是由创建对象触发的,即:对象 = 类名();而对于__call__方法的执行是由对象后加括号触发的,即:对象()或者类()()
1 | class Foo: |
6. __dict__
- 类或对象中的所有属性
类的实例属性属于对象;类中的类属性和方法等属于类,即:
1 | class Province(object): |
7. __str__
- 如果一个类中定义了
__str__方法,那么在打印 对象 时,默认输出该方法的返回值。1
2
3
4
5
6
7
8class Foo:
def __str__(self):
return 'laowang'
obj = Foo()
print(obj)
# 输出:laowang
8、__getitem__、__setitem__、__delitem__
- 用于索引操作,如字典。以上分别表示获取、设置、删除数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# -*- coding:utf-8 -*-
class Foo(object):
def __getitem__(self, key):
print('__getitem__', key)
def __setitem__(self, key, value):
print('__setitem__', key, value)
def __delitem__(self, key):
print('__delitem__', key)
obj = Foo()
result = obj['k1'] # 自动触发执行 __getitem__
obj['k2'] = 'laowang' # 自动触发执行 __setitem__
del obj['k1'] # 自动触发执行 __delitem__
9、__getslice__、__setslice__、__delslice__
- 该三个方法用于分片操作,如:列表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# -*- coding:utf-8 -*-
class Foo(object):
def __getslice__(self, i, j):
print('__getslice__', i, j)
def __setslice__(self, i, j, sequence):
print('__setslice__', i, j)
def __delslice__(self, i, j):
print('__delslice__', i, j)
obj = Foo()
obj[-1:1] # 自动触发执行 __getslice__
obj[0:1] = [11,22,33,44] # 自动触发执行 __setslice__
del obj[0:2] # 自动触发执行 __delslice__
面向对象设计
- 继承 - 是基于Python中的属性查找(如X.name)
- 多态 - 在X.method方法中,method的意义取决于X的类型
- 封装 - 方法和运算符实现行为,数据隐藏默认是一种惯例
参考实例
腾讯即时通信模块,初级封装
1 | #! /usr/bin/env python |
微信开发包,python实现, wechat_sdk开发
1 | http://wechat-python-sdk.com/ |
截取部分代码,学习类的设计
1 | from __future__ import unicode_literals |
思维锻炼
- 设计讲师和学生类,讲师有上课,备课等方法,学生有听课,做练习等方法,均有姓名、性别、年龄等基本属性
- 设计聊天Message类
with与“上下文管理器”
如果你有阅读源码的习惯,可能会看到一些优秀的代码经常出现带有 “with” 关键字的语句,它通常用在什么场景呢?
对于系统资源如文件、数据库连接、socket 而言,应用程序打开这些资源并执行完业务逻辑之后,必须做的一件事就是要关闭(断开)该资源。
比如 Python 程序打开一个文件,往文件中写内容,写完之后,就要关闭该文件,否则会出现什么情况呢?极端情况下会出现 “Too many open files” 的错误,因为系统允许你打开的最大文件数量是有限的。
同样,对于数据库,如果连接数过多而没有及时关闭的话,就可能会出现 “Can not connect to MySQL server Too many connections”,因为数据库连接是一种非常昂贵的资源,不可能无限制的被创建。
来看看如何正确关闭一个文件。
1. 普通版
1 | def m1(): |
这样写有一个潜在的问题,如果在调用 write 的过程中,出现了异常进而导致后续代码无法继续执行,close 方法无法被正常调用,因此资源就会一直被该程序占用者释放。那么该如何改进代码呢?
2. 进阶版
1 | def m2(): |
改良版本的程序是对可能发生异常的代码处进行 try 捕获,使用 try/finally 语句,该语句表示如果在 try 代码块中程序出现了异常,后续代码就不再执行,而直接跳转到 except 代码块。而无论如何,finally 块的代码最终都会被执行。因此,只要把 close 放在 finally 代码中,文件就一定会关闭。
3. 高级版
1 | def m3(): |
一种更加简洁、优雅的方式就是用 with 关键字。open 方法的返回值赋值给变量 f,当离开 with 代码块的时候,系统会自动调用 f.close() 方法, with 的作用和使用 try/finally 语句是一样的。那么它的实现原理是什么?在讲 with 的原理前要涉及到另外一个概念,就是上下文管理器(Context Manager)。
什么是上下文(context)
上下文在不同的地方表示不同的含义,要感性理解。context其实说白了,和文章的上下文是一个意思,在通俗一点,我觉得叫环境更好。….
林冲大叫一声“啊也!”….
问:这句话林冲的“啊也”表达了林冲怎样的心里?
答:啊你妈个头啊!
看,一篇文章,给你摘录一段,没前没后,你读不懂,因为有语境,就是语言环境存在,一段话说了什么,要通过上下文(文章的上下文)来推断。
app点击一个按钮进入一个新的界面,也要保存你是在哪个屏幕跳过来的等等信息,以便你点击返回的时候能正确跳回,如果不存肯定就无法正确跳回了。
看这些都是上下文的典型例子,理解成环境就可以,(而且上下文虽然叫上下文,但是程序里面一般都只有上文而已,只是叫的好听叫上下文。。进程中断在操作系统中是有上有下的,不过不这个高深的问题就不要深究了。。。)
上下文管理器
任何实现了 __enter__() 和 __exit__() 方法的对象都可称之为上下文管理器,上下文管理器对象可以使用 with 关键字。显然,文件(file)对象也实现了上下文管理器。
那么文件对象是如何实现这两个方法的呢?我们可以模拟实现一个自己的文件类,让该类实现 __enter__() 和 __exit__() 方法。
1 | class File(): |
__enter__() 方法返回资源对象,这里就是你将要打开的那个文件对象,__exit__() 方法处理一些清除工作。
因为 File 类实现了上下文管理器,现在就可以使用 with 语句了。
1 | with File('out.txt', 'w') as f: |
这样,你就无需显示地调用 close 方法了,由系统自动去调用,哪怕中间遇到异常 close 方法也会被调用。
实现上下文管理器的另外方式
Python 还提供了一个 contextmanager 的装饰器,更进一步简化了上下文管理器的实现方式。通过 yield 将函数分割成两部分,yield 之前的语句在 enter 方法中执行,yield 之后的语句在 exit 方法中执行。紧跟在 yield 后面的值是函数的返回值。
1 | from contextlib import contextmanager |
调用
1 | with my_open('out.txt', 'w') as f: |
总结
Python 提供了 with 语法用于简化资源操作的后续清除操作,是 try/finally 的替代方法,实现原理建立在上下文管理器之上。此外,Python 还提供了一个 contextmanager 装饰器,更进一步简化上下管理器的实现方式。
※args、※※kwargs的另外用处拆包
1 | def test1(a,b,*args,**kwargs): |
1 | def test2(a,b,*args,**kwargs): |
1 | def test2(a,b,*args,**kwargs): |
1 | def test2(a,b,*args,**kwargs): |

