多任务的概念
简单地说,就是操作系统可以同时运行多个任务。
现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行多任务。由于CPU执行代码都是顺序执行的,那么,单核CPU是怎么执行多任务的呢?
答案就是操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,执行0.01秒……这样反复执行下去。表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像所有任务都在同时执行一样。
真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行。
注意:
- 并发:指的是任务数多于cpu核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
- 并行:指的是任务数小于等于cpu核数,即任务真的是一起执行的
线程
python的thread模块是比较底层的模块,python的threading模块是对thread做了一些包装的,可以更加方便的被使用
使用threading模块
单线程执行
1 | #coding=utf-8 |
多线程执行
1 | #coding=utf-8 |
说明
- 可以明显看出使用了多线程并发的操作,花费时间要短很多
- 当调用start()时,才会真正的创建线程,并且开始执行
主线程会等待所有的子线程结束后才结束
1 | #coding=utf-8 |
查看线程数量
1 | #coding=utf-8 |
线程-注意点
线程执行代码的封装
通过使用threading模块能完成多任务的程序开发,为了让每个线程的封装性更完美,所以使用threading模块时,往往会定义一个新的子类class,只要继承threading.Thread就可以了,然后重写run方法
示例如下:
1 | #coding=utf-8 |
说明
- python的threading.Thread类有一个run方法,用于定义线程的功能函数,可以在自己的线程类中覆盖该方法。而创建自己的线程实例后,通过Thread类的start方法,可以启动该线程,交给python虚拟机进行调度,当该线程获得执行的机会时,就会调用run方法执行线程。
线程的执行顺序
1 | #coding=utf-8 |
说明
- 从代码和执行结果我们可以看出,多线程程序的执行顺序是不确定的。当执行到sleep语句时,线程将被阻塞(Blocked),到sleep结束后,线程进入就绪(Runnable)状态,等待调度。而线程调度将自行选择一个线程执行。上面的代码中只能保证每个线程都运行完整个run函数,但是线程的启动顺序、run函数中每次循环的执行顺序都不能确定。
修改上述代码,使之能按顺序执行
1 | #!/usr/bin/env python |
总结
- 每个线程默认有一个名字,尽管上面的例子中没有指定线程对象的name,但是python会自动为线程指定一个名字。
- 当线程的run()方法结束时该线程完成。
- 无法控制线程调度程序,但可以通过别的方式来影响线程调度的方式。
多线程-共享全局变量
1 | #!/usr/bin/env python |
列表当做实参传递到线程中
1 | #!/usr/bin/env python |
总结
- 在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据
- 缺点就是,线程是对全局变量随意遂改可能造成多线程之间对全局变量的混乱(即线程非安全)
多线程-共享全局变量问题
多线程开发可能遇到的问题
假设两个线程t1和t2都要对全局变量g_num(默认是0)进行加1运算,t1和t2都各对g_num加10次,g_num的最终的结果应该为20。
但是由于是多线程同时操作,有可能出现下面情况:
- 在g_num=0时,t1取得g_num=0。此时系统把t1调度为”sleeping”状态,把t2转换为”running”状态,t2也获得g_num=0
- 然后t2对得到的值进行加1并赋给g_num,使得g_num=1
- 然后系统又把t2调度为”sleeping”,把t1转为”running”。线程t1又把它之前得到的0加1后赋值给g_num。
- 这样导致虽然t1和t2都对g_num加1,但结果仍然是g_num=1
测试1
1 | #!/usr/bin/env python |
运行结果:
1 | ---线程创建之前g_num is 0--- |
测试2
1 | #!/usr/bin/env python |
运行结果:
1 | ---线程创建之前g_num is 0--- |
结论
- 如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确
同步的概念
同步就是协同步调,按预定的先后次序进行运行。如:你说完,我再说。
“同”字从字面上容易理解为一起动作,其实不是,”同”字应是指协同、协助、互相配合。
如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B执行,再将结果给A;A再继续操作。
解决线程同时修改全局变量的方式
可以通过线程同步来进行解决,思路如下:
- 系统调用t1,然后获取到g_num的值为0,此时上一把锁,即不允许其他线程操作g_num
- t1对g_num的值进行+1
- t1解锁,此时g_num的值为1,其他的线程就可以使用g_num了,而且是g_num的值不是0而是1
- 同理其他线程在对g_num进行修改时,都要先上锁,处理完后再解锁,在上锁的整个过程中不允许其他线程访问,就保证了数据的正确性
互斥锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
threading模块中定义了Lock类,可以方便的处理锁定:
1 | # 创建锁 |
注意:
- 如果这个锁之前是没有上锁的,那么acquire不会堵塞
- 如果在调用acquire对这个锁上锁之前 它已经被 其他线程上了锁,那么此时acquire会堵塞,直到这个锁被解锁为止
使用互斥锁完成2个线程对同一个全局变量各加100万次的操作
1 | #!/usr/bin/env python |
运行结果:
1 | ---test1---g_num=1940444 |
可以看到最后的结果,加入互斥锁后,其结果与预期相符。
上锁解锁过程
当一个线程调用锁的acquire()方法获得锁时,锁就进入“locked”状态。
每次只有一个线程可以获得锁。如果此时另一个线程试图获得这个锁,该线程就会变为“blocked”状态,称为“阻塞”,直到拥有锁的线程调用锁的release()方法释放锁之后,锁进入“unlocked”状态。
线程调度程序从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入运行(running)状态。
总结
锁的好处:
- 确保了某段关键代码只能由一个线程从头到尾完整地执行
锁的坏处: - 阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了
- 由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁
死锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
尽管死锁很少发生,但一旦发生就会造成应用的停止响应。下面看一个死锁的例子
1 | import threading |
运行此代码会发现此时已经进入到了死锁状态,可以使用ctrl-c退出
避免死锁
- 程序设计时要尽量避免(银行家算法)
- 添加超时时间等
附录-银行家算法
[背景知识]
一个银行家如何将一定数目的资金安全地借给若干个客户,使这些客户既能借到钱完成要干的事,同时银行家又能收回全部资金而不至于破产,这就是银行家问题。这个问题同操作系统中资源分配问题十分相似:银行家就像一个操作系统,客户就像运行的进程,银行家的资金就是系统的资源。
[问题的描述]
一个银行家拥有一定数量的资金,有若干个客户要贷款。每个客户须在一开始就声明他所需贷款的总额。若该客户贷款总额不超过银行家的资金总数,银行家可以接收客户的要求。客户贷款是以每次一个资金单位(如1万RMB等)的方式进行的,客户在借满所需的全部单位款额之前可能会等待,但银行家须保证这种等待是有限的,可完成的。
例如:有三个客户C1,C2,C3,向银行家借款,该银行家的资金总额为10个资金单位,其中C1客户要借9各资金单位,C2客户要借3个资金单位,C3客户要借8个资金单位,总计20个资金单位。某一时刻的状态如图所示。
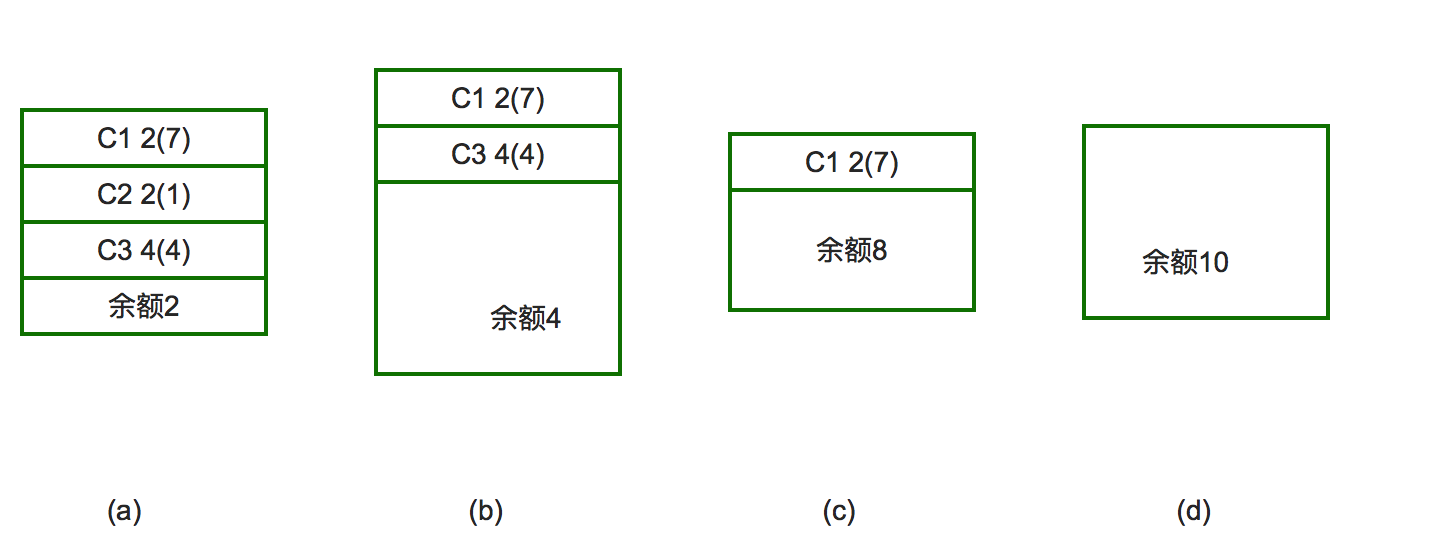
对于a图的状态,按照安全序列的要求,我们选的第一个客户应满足该客户所需的贷款小于等于银行家当前所剩余的钱款,可以看出只有C2客户能被满足:C2客户需1个资金单位,小银行家手中的2个资金单位,于是银行家把1个资金单位借给C2客户,使之完成工作并归还所借的3个资金单位的钱,进入b图。同理,银行家把4个资金单位借给C3客户,使其完成工作,在c图中,只剩一个客户C1,它需7个资金单位,这时银行家有8个资金单位,所以C1也能顺利借到钱并完成工作。最后(见图d)银行家收回全部10个资金单位,保证不赔本。那麽客户序列{C1,C2,C3}就是个安全序列,按照这个序列贷款,银行家才是安全的。否则的话,若在图b状态时,银行家把手中的4个资金单位借给了C1,则出现不安全状态:这时C1,C3均不能完成工作,而银行家手中又没有钱了,系统陷入僵持局面,银行家也不能收回投资。
综上所述,银行家算法是从当前状态出发,逐个按安全序列检查各客户谁能完成其工作,然后假定其完成工作且归还全部贷款,再进而检查下一个能完成工作的客户,……。如果所有客户都能完成工作,则找到一个安全序列,银行家才是安全的。
案例:多任务版udp聊天器
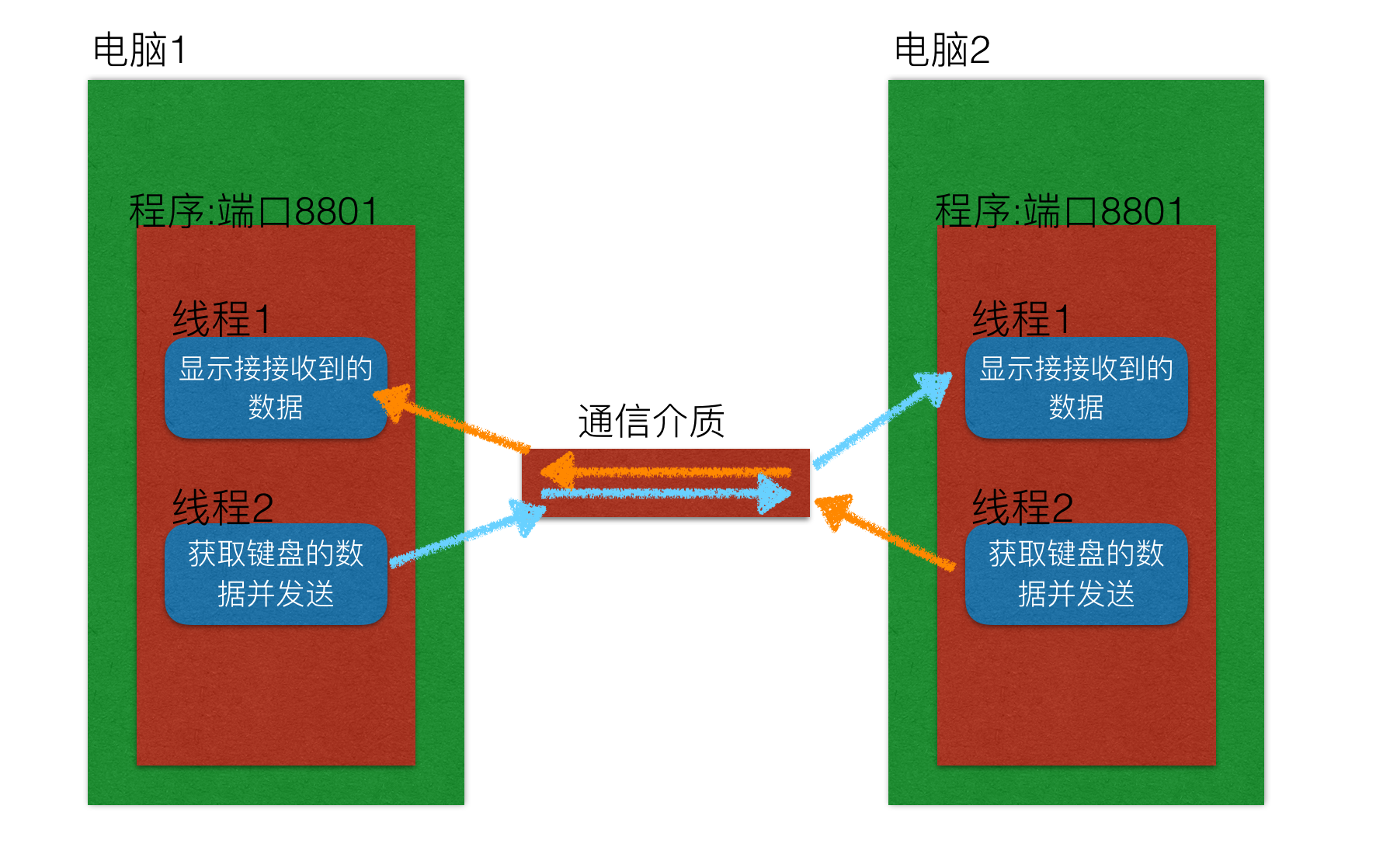
说明
- 编写一个有2个线程的程序
- 线程1用来接收数据然后显示
- 线程2用来检测键盘数据然后通过udp发送数据
参考代码:
1 | import socket |

