进程以及状态
进程
程序:例如xxx.py这是程序,是一个静态的
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。
不仅可以通过线程完成多任务,进程也是可以的
进程的状态
工作中,任务数往往大于cpu的核数,即一定有一些任务正在执行,而另外一些任务在等待cpu进行执行,因此导致了有了不同的状态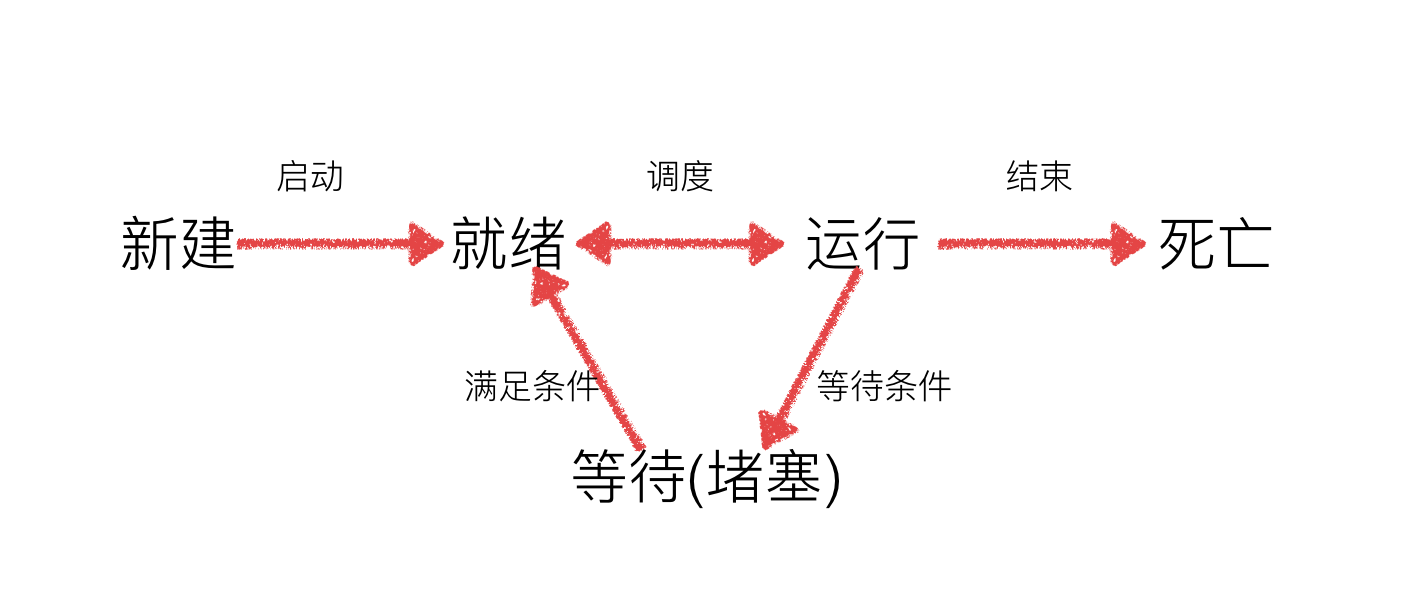
- 就绪态:运行的条件都已经慢去,正在等在cpu执行
- 执行态:cpu正在执行其功能
- 等待态:等待某些条件满足,例如一个程序sleep了,此时就处于等待态
进程的创建-multiprocessing
multiprocessing模块就是跨平台版本的多进程模块,提供了一个Process类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情
2个while循环一起执行
1 | from multiprocessing import Process |
说明
- 创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动
进程pid
1 | from multiprocessing import Process |
Process语法结构
Process([group [, target [, name [, args [, kwargs]]]]])
- target:如果传递了函数的引用,可以任务这个子进程就执行这里的代码
- args:给target指定的函数传递的参数,以元组的方式传递
- kwargs:给target指定的函数传递命名参数
- name:给进程设定一个名字,可以不设定
- group:指定进程组,大多数情况下用不到
Process创建的实例对象的常用方法:
- start():启动子进程实例(创建子进程)
- is_alive():判断进程子进程是否还在活着
- join([timeout]):是否等待子进程执行结束,或等待多少秒
- terminate():不管任务是否完成,立即终止子进程
Process创建的实例对象的常用属性:
- name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
- pid:当前进程的pid(进程号)
给子进程指定的函数传递参数
1 | from multiprocessing import Process |
进程间不共享全局变量
1 | from multiprocessing import Process |
运行结果:
1 | in process1 pid=11349 ,nums=[11, 22] |
进程、线程对比
功能
- 进程,能够完成多任务,比如 在一台电脑上能够同时运行多个QQ
- 线程,能够完成多任务,比如 一个QQ中的多个聊天窗口
定义的不同
- 进程是系统进行资源分配和调度的一个独立单位.
- 线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
区别
- 一个程序至少有一个进程,一个进程至少有一个线程.
- 线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
![]/images_jincheng/002.png)线程不能够独立执行,必须依存在进程中
- 可以将进程理解为工厂中的一条流水线,而其中的线程就是这个流水线上的工人
优缺点
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。
进程间通信-Queue
Process之间有时需要通信,操作系统提供了很多机制来实现进程间的通信。
Queue的使用
可以使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue本身是一个消息列队程序,首先用一个小实例来演示一下Queue的工作原理:
1 | from multiprocessing import Queue |
运行结果:
1 | False |
说明
初始化Queue()对象时(例如:q=Queue()),若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头);
- Queue.qsize():返回当前队列包含的消息数量;
- Queue.empty():如果队列为空,返回True,反之False ;
- Queue.full():如果队列满了,返回True,反之False;
- Queue.get([block[, timeout]]):获取队列中的一条消息,然后将其从列队中移除,block默认值为True;
1)如果block使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出”Queue.Empty”异常;
2)如果block值为False,消息列队如果为空,则会立刻抛出”Queue.Empty”异常;
- Queue.get_nowait():相当Queue.get(False);
- Queue.put(item,[block[, timeout]]):将item消息写入队列,block默认值为True;
1)如果block使用默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出”Queue.Full”异常;
2)如果block值为False,消息列队如果没有空间可写入,则会立刻抛出”Queue.Full”异常;
- Queue.put_nowait(item):相当Queue.put(item, False);
Queue实例
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
1 | from multiprocessing import Process, Queue |
进程池Pool
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务,请看下面的实例:
1 | from multiprocessing import Pool |
运行结果:
1 | ----start---- |
multiprocessing.Pool常用函数解析:
- apply_async(func[, args[, kwds]]) :使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表;
- close():关闭Pool,使其不再接受新的任务;
- terminate():不管任务是否完成,立即终止;
- join():主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用;
进程池中的Queue
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否则会得到一条如下的错误信息:
RuntimeError: Queue objects should only be shared between processes through inheritance.
下面的实例演示了进程池中的进程如何通信:
1 | # 修改import中的Queue为Manager |
运行结果:
1 | (11095) start |
应用:文件夹copy器(多进程版)
1 | import multiprocessing |

